Papers Explained 170: Prometheus

A 13B fully open source evaluation LLM trained on Feedback Collection curated using GPT-4 (in this work).
This work constructs Feedback Collection, a new dataset that consists of 1K fine-grained score rubrics, 20K instructions, and 100K responses and language feedback generated by GPT-4.
Prometheus is trained using this dataset. It is a 13B fully open source evaluator LLM that can assess any given long-form text based on customized score rubric provided by the user.

The project is available at GitHub.
The Feedback Collection Dataset
The 4 main considerations during dataset construction are:
- Including as many reference materials (i.e. reference answer, and scoring rubric) as possible
- Maintaining a uniform length among the reference answers for each score (1 to 5) to prevent undesired length bias
- Maintaining a uniform score distribution to prevent undesired decision bias
- Limiting the scope of our instructions and responses to realistic situations where a user is interacting with a LLM.
Taking these into consideration, each instance within the Feedback Collection comprises four components for the input and two components in the output (feedback, score).

Input Components:
- Instruction: An instruction that a user would prompt to an arbitrary LLM.
- Response to Evaluate: A response to the instruction that the evaluator LM has to evaluate.
- Customized Score Rubric: A specification of novel criteria decided by the user. The evaluator should focus on this aspect during evaluation. The rubric consists of (1) a description of the criteria and (2) a description of each scoring decision (1 to 5).
- Reference Answer: A reference answer that would receive a score of 5. Instead of requiring the evaluator LM to solve the instruction, it enables the evaluator to use the mutual information between the reference answer and the response to make a scoring decision.
Output Components:
- Feedback: A rationale of why the provided response would receive a particular score. This is analogous to Chain-of-Thoughts (CoT), making the evaluation process interpretable.
- Score: An integer score for the provided response that ranges from 1 to 5.

Dataset Construction Process

The collection process consists of:
- Manual curation of 50 initial seed rubrics
- Expansion of 1K new score rubrics through GPT-4: 4 randomly sampled rubrics are used as demonstrations for in context learning. GPT-4 is also prompted to paraphrase the newly generated rubrics in order to ensure Prometheus could generalize to the similar score rubric that uses different words.
- Augmentation of realistic instructions: GPT-4 is prompted to generate 20K unique instructions that are highly relevant to the given score rubric.
- Augmentation of the remaining components in the training instances (i.e. responses including the reference answers, feedback, and scores)
- For each score rubric, 20 instructions are generated, along with 5 responses and feedback for each instruction.
- To eliminate decision bias when fine-tuning the evaluator LM, an equal number of 20,000 responses are generated for each score.
- For responses with a score of 5, two distinctive responses are generated, with one used as a reference answer.




Fine-Tuning the Evaluator LLM
Llama-2-Chat (7B & 13B) are fine tuned on Feedback Collection to obtain Prometheus. Similar to Chain-of-Thought Fine Tuning, Prometheus is fine-tuned to sequentially generate the feedback and then the score. It is highlighted that it is important to include a phrase such as ‘[RESULT]’ in between the feedback and the score to prevent degeneration during inference.
Experimental Setup
The evaluator isevaluated using human evaluation and GPT-4 evaluation and it is measured how similarly the evaluator models could closely simulate them. Two types of evaluation methods are used: Absolute Grading and Ranking Grading.
Absolute Grading:
The evaluator LM generates a feedback and score within the range of 1 to 5 given an instruction, a response to evaluate, and reference materials. Three experiments are conducted in this setting:
- Measuring the correlation with human evaluators (Section 5.1) using 3 correlation metrics: Pearson, Kdendall-Tau, and Spearman.
- Comparing the quality of the feedback using human evaluation by conducting a pairwise comparison between the feedback generated by Prometheus, GPT-3.5-Turbo, and GPT-4.
- Measuring the correlation with GPT-4 evaluation.
Four benchmarks are used to measure the correlation with human evaluation and GPT-4 evaluation:
- Feedback Bench: A dataset generated with the same procedure as the Feedback Collection, divided into two subsets (Seen Rubric and Unseen Rubric).
- Vicuna Bench: An adapted dataset from Vicuna with hand-crafted customized score rubrics for each test prompt.
- MT Bench: An adapted dataset from MT Bench with hand-crafted customized score rubrics and generated reference answers using GPT-4.
- FLASK Eval: An adapted dataset from FLASK with 12 score rubrics.
Ranking Grading:
The evaluator LM is tested on existing human preference benchmarks using accuracy as the metric. The experiment checks whether the evaluator LM could give a higher score to the response that is preferred by human evaluators.The biggest challenge is that the evaluator LM trained in an Absolute Grading setting may give the same score for both candidates, so a temperature of 1.0 is used when evaluating each candidate independently and iterating until there is a winner.
Two benchmarks are used to measure the accuracy with human preference datasets:
- MT Bench Human Judgement: A dataset from MT Bench with a tie option and no iterative inference required.
- HHH Alignment: A dataset from Anthropic with 221 pairs measuring preference accuracy in Helpfulness, Harmlessness, Honesty, and General (Other) among two response choices.
Evaluation

Can Prometheus Simulate Human Evaluation
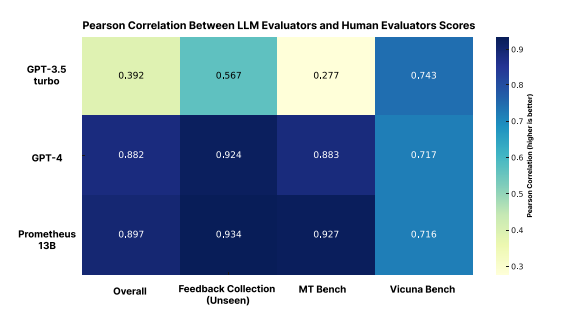
Correlation with Human Scoring: Prometheus showed a high correlation (0.897 Pearson correlation) with human scores, on par with GPT-4 (0.882) and significantly higher than GPT-3.5-Turbo (0.392).
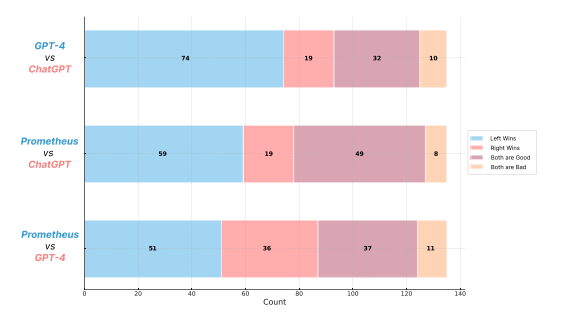
Pairwise Comparison of the Feedback with Human Evaluation: Prometheus was preferred over GPT-4 58.62% of the time and over GPT-3.5-Turbo 79.57% of the time, indicating that its feedback is meaningful and helpful
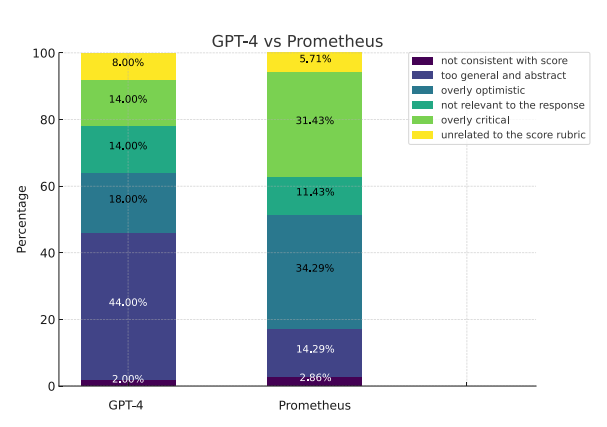
Analysis of Why Prometheus’s Feedback was Preferred: While GPT-4 was mainly not chosen due to providing general or abstract feedback, Prometheus was mainly not chosen because it was too critical about the given response. In conclusion GPT-4 tends to be more neutral and abstract, whereas Prometheus shows a clear trend of expressing its opinion of whether the given response is good or not.
Can Prometheus Simulate GPT4 Evaluation
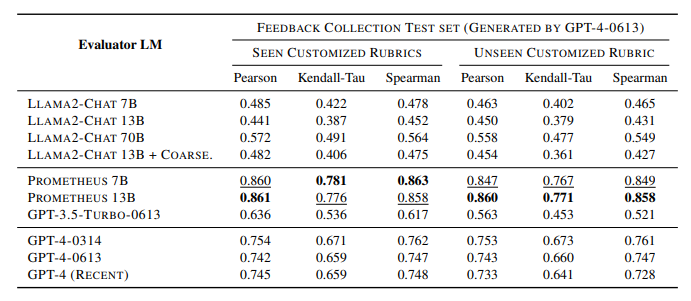
- Llama-2-Chat 13B performs worse than its 7B model and slightly better when scaled up to 70B, suggesting that simply scaling up model size does not improve evaluation capabilities.
- Prometheus 13B outperforms Llama-2-Chat 13B and its larger version (70B), as well as GPT-3.5-Turbo-0613, GPT-4, and different versions of GPT-4 by a significant margin in terms of Pearson correlation on the seen and unseen rubric set.
- The slight improvement in performance when training on coarse-grained score rubrics (Llama2-Chat 13B + Coarse) suggests that a wide range of score rubrics is important for handling diverse user needs
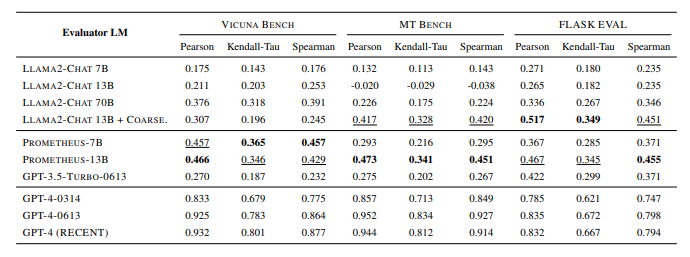
- Prometheus also shows improvements over its base model on the Vicuna Bench, MT Bench, and Flask Eval datasets, but still lags behind GPT-4.
- A specific training approach with the Flask Eval dataset (Llama2-Chat 13B + Coarse) outperforms Prometheus on the Flask Eval dataset, indicating that training directly on the evaluation dataset can be beneficial for task-specific evaluators.
Can Prometheus Function as a Reward Model
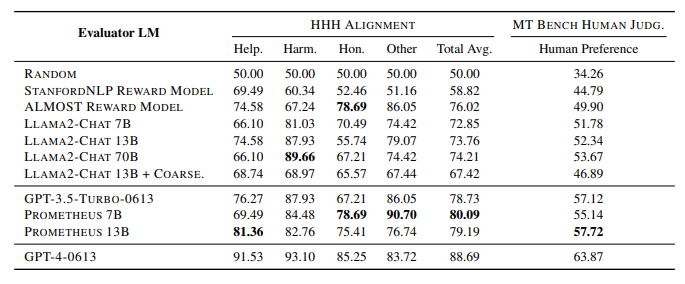
- Llama-2-Chat surprisingly performed well with reasonable accuracy, which was unexpected as it was not directly trained on ranking evaluation instances. This performance was conjectured to be influenced by the model’s base training with RLHF.
- Training Llama-2-Chat on coarse-grained score rubrics (Llama2-Chat 13B + Coarse) led to a decrease in performance.
- Prometheus-13B outperformed its base model Llama-2-Chat by a significant margin of +5.43% on the HHH Alignment dataset and +5.38% on the MT Bench Human Judgment dataset.
- The results suggest that training on an absolute grading scheme can potentially improve performance on a ranking grading scheme, indicating the potential of using Prometheus as reward models in RLHF
Paper
Prometheus: Inducing Fine-grained Evaluation Capability in Language Models 2310.08491
Recommended Reading [LLM Evaluation]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
