Papers Explained 169: mBART

mBART is a sequence-to-sequence denoising auto-encoder pre-trained on large-scale monolingual corpora in many languages using the BART objective.
Architecture

A standard sequence-to-sequence Transformer architecture is used, with 12 layers of encoder and 12 layers of decoder. The model dimension is set at 1024, and it has 16 heads, corresponding to approximately 680 million parameters. An additional layer-normalization layer is included on top of both the encoder and decoder, which is stabilized at FP16 precision through training.
Multilingual Denoising Pre-training
A subset of 25 languages, extracted from the Common Crawl (CC), known as CC25, is pre-trained.

A sentencepiece model is used for tokenization, with a vocabulary of 250,000 subword tokens.
Noise function
Two types of noise are used. Spans of text are first removed and replaced with a mask token. The words in each instance are then masked, with 35% randomly sampled according to a Poisson distribution (λ = 3.5). The order of sentences within each instance is also permuted.
The decoder input is the original text with one position offset. A language id symbol is used as the initial token to predict the sentence.
Pre-trained Models
- mBART25 a model pretrained on all 25 languages.
- mBART06 a model pretrained on a subset of six European languages: Ro, It, Cs, Fr, Es and En.
- mBART02 pre-trained bilingual models, using English and one other language for four language pairs: En-De, En-Ro, En-It.
- BART-En/Ro pre-trained monolingual BART models on the same En and Ro corpus only.
Sentence-level Machine Translation
Datasets
24 pairs of publicly available parallel corpora that cover all the languages in CC25 are gathered.
- Most pairs are from previous WMT (Gu, Kk, Tr, Ro, Et, Lt, Fi, Lv, Cs, Es, Zh, De, Ru, Fr ↔ En) and IWSLT (Vi, Ja, Ko, Nl, Ar, It ↔ En) competitions.
- FLoRes pairs (En-Ne and EnSi) are also used
- En-Hi from IITB
- En-My from WAT19
The datasets is divided into into three categories —low resource (less than 1M sentence pairs), medium resource (between 1M and 10M), and high resource (more than 10M).
Fine-tuning & Decoding
The multilingual pre-trained language models are fine-tuned on a single pair of parallel bitext data, with the source language text being fed into the encoder and the target language text being decoded.

Pre-training consistently improves over a randomly initialized baseline, with particularly large gains on low resource language pairs.
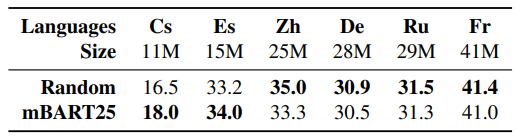

Document-level Machine Translation
mBART is evaluated on document-level machine translation tasks, where the goal is to translate segments of text that contain more than one sentence. Document fragments of up to 512 tokens are used during pre-training, enabling models to learn dependencies between sentences, this pre-training significantly improves document-level translation.
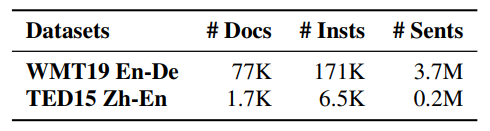
Datasets
Performance is evaluated on two common document-level MT datasets: WMT19 En-De and TED15 Zh-En.

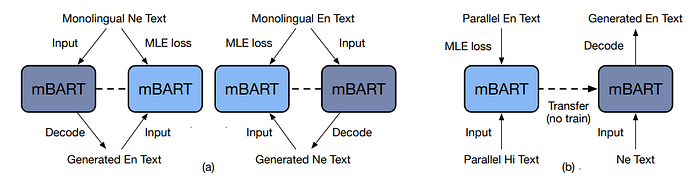
Unsupervised Machine Translation
Paper
Multilingual Denoising Pre-training for Neural Machine Translation 2001.08210
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
