Papers Explained 167: Monte Carlo Tree Self-refine

Monte Carlo Tree Self-refine combines LLMs with Monte Carlo Tree Search (MCTS) to improve performance in complex mathematical reasoning tasks. MCTSr addresses the limitations of LLMs in strategic and mathematical reasoning by incorporating systematic exploration and heuristic self-refine mechanisms to enhance decision-making frameworks within LLMs.
I have implemented the paper using Langchain, the code is available at GitHub.
Monte Carlo Tree Search
Monte Carlo Tree Search (MCTS) is a decision-making algorithm used in games and complex decision processes. It operates by building a search tree and simulating outcomes to estimate the value of actions. The algorithm consists of four key phases:
- Selection: Starting from the root, the algorithm navigates through promising child nodes based on specific strategies (e.g., Upper Confidence Bound applied on Trees, UCT) until a leaf node is reached.
- Expansion: At the leaf node, unless it represents a terminal state of the game, one or more feasible new child nodes are added to illustrate potential future moves.
- Simulation or Evaluation: From the newly added node, the algorithm conducts random simulations (often termed “rollouts”) by selecting moves arbitrarily until a game’s conclusion is reached, thereby evaluating the node’s potential.
- Backpropagation: Post-simulation, the outcome (win, loss, or draw) is propagated back to the root, updating the statistical data (e.g., wins, losses) of each traversed node to inform future decisions.
The Upper Confidence Bound applied on Trees (UCT) algorithm is crucial for the selection phase in MCTS, balancing exploration and exploitation by choosing actions that maximize the following formula:

Where X¯ j is the average reward of action j, NC is the total visited times of the father node, and nj is the number of times node j has been visited for simulation, C is a constant to balancing exploitation and exploration.
MCT Self-Refine
The MCT Self-Refine (MCTSr) algorithm combines Monte Carlo Tree Search (MCTS) with large language models to iteratively refine mathematical problem solutions. The algorithm represents the refinement process as a search tree, where nodes represent different answer versions and edges denote attempts at improvement.
The operational workflow of MCTSr follows the general pattern of MCTS:
- Problem instance: P is the problem being addressed.
- Node set: A is the set of nodes, each representing a potential answer to P.
- Action set: M is the set of actions available at each node, representing possible self-refine modifications to an answer.
- Reward function: R samples self-rewards for nodes based on the quality and effectiveness of the modifications.
- Self-reward storage: Ra stores all self-rewards sampling results for a given node with function R.
- Termination criterion: T determines when to stop the search process, such as reaching a maximum number of iterations or achieving satisfactory answer quality.
- Value function: Q(a) estimates the worth of an answer node a based on accumulated rewards Ra and backpropagations from child nodes.
- Upper Confidence Bound (UCB): U(a) balances between exploitation and exploration by considering the value function and the number of visits to node a, N(a).
- Parent node: Father(a) returns the parent node of a given node a, or null if it’s a root node.
- Child nodes: Children(a) returns the set of all child nodes for a given node a, representing all possible states derived from a by executing actions m ∈ M.
- Visit count: N(a) is the total number of visits to node a, used to calculate its UCB value and assess exploration and exploitation status.
By iteratively refining answers using self-reflective driven self-improvement and sampling rewards with function R, MCTSr aims to find high-quality solutions to mathematical problems.
The workflow of the algorithm is as follows:
- Initialization: Establish a root node using a naive model-generated answer and a dummy response (“I don’t know”) to minimize model overfitting tendencies.
- Selection: Use a value function Q to rank all answers that were not fully expanded. Select the highest-valued node for further exploration and refinement using a greedy strategy.
- Self-Refine: The selected answer undergoes optimization using the Self-Refine framework. Generate a feedback m, guiding the refining process to produce an enhanced answer a’.
- Self-Evaluation: Score the refined answer to sample a reward value and compute its Q value. Use model self-reward feedback and constraints such as:
- Prompt Constraint: Adhere to strict standards during reward scoring.
- Full Score Suppression: Reduce any reward above 95 by a constant amount.
- Repeated Sampling: Sample the node’s rewards multiple times to enhance reliability.
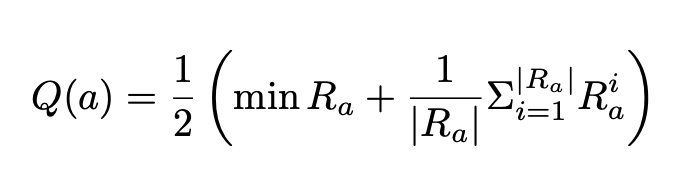
where Q(a) is the quality value of answer a, Ra is the set of reward samples for a, min Ra is the minimum reward in Ra, |Ra| is the number of samples, and Σ |Ra| i=1 Ri a is the sum of all rewards in Ra.
- Backpropagation: Propagate the value of the refined answer backward to its parent node and other related nodes to update the tree’s value information. If the Q value of any child node changes, update the parent node’s Q value.
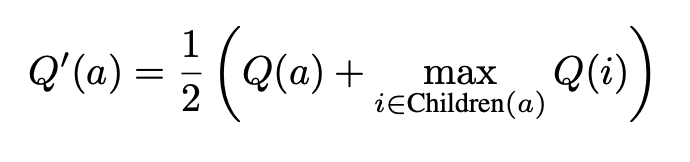
Where Q′ (a) is the updated quality value of answer a that consider the impact from its children nodes, Q(a) is the naive quality value only consider its reward samplings, and maxi∈Children(a) Q(i) represents the highest quality value among the children of a.
- UCT Update: After updating all nodes’ Q values, identify a collection C of candidate nodes for further expansion or selection. Use the UCT update formula to update the UCT values of all nodes for the next selection stage:
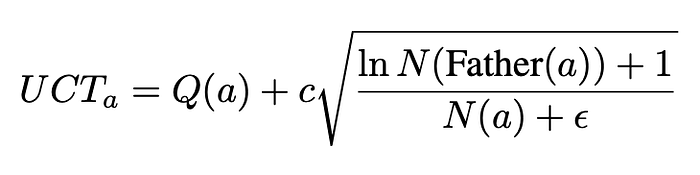
where Q(a) is the Q value of answer a, N(·) is the total visited times of given nodes, c is a constant to balancing exploitation and exploration, ϵ is a small constant for avoid devided-by-zero.
- Termination Function: The search terminates when one or more conditions are met, such as:
- Early Stopping: Improvements in search results diminish or consecutive searches yield repetitive outcomes.
- Search Constraints: Reach a predetermined limit of rollouts or maximum depth constraint.
- Advanced Criteria Based on Language Model Logits: Meet predefined metrics derived from the language model’s logits.
Once the termination function condition is satisfied, gather the best answers from tree nodes according to Q values or other conditions.
Evaluation
GSM Benchmarks
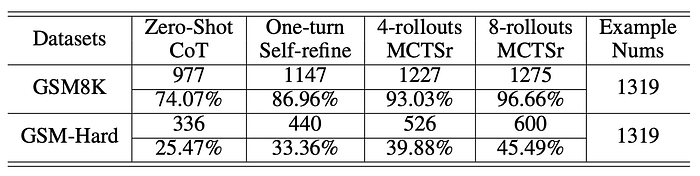
- A direct correlation exists between the number of MCTSr rollouts and success rates, particularly on the GSM8K dataset.
- Success rates significantly improve as iterations (rollouts) increase in GSM8K.
- GSM-Hard dataset shows a performance ceiling even at higher rollout numbers, suggesting limitations of current strategies for complex problems.
MATH Benchmark
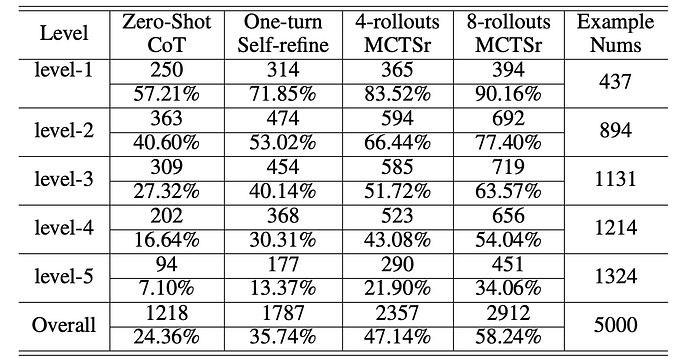
- Level-1 Performance: The 8-rollouts MCTSr achieved a 90.16% success rate, solving 394 out of 437 problems.
- Level-5 Performance: The 8-rollouts MCTSr achieved a 34.06% success rate, solving 451 out of 1324 problems.
- Overall Performance: The 8-rollouts MCTSr achieved a cumulative success rate of 58.24%, solving 2912 out of 5000 problems. This represents a significant improvement over the Zero-Shot CoT’s initial rate of 24.36%.
- Increasing the number of rollouts consistently correlated with improved success rates.
Olympiad-level Benchmarks
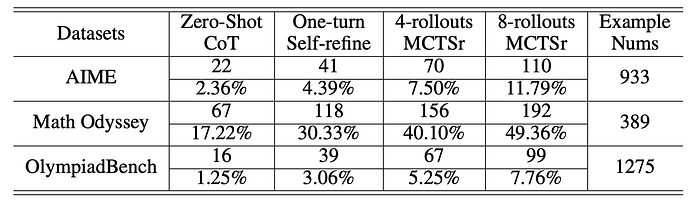

- MCTSr consistently outperformed zero-shot CoT across all three datasets.
- Increasing the number of rollouts directly correlated with higher success rates, demonstrating the algorithm’s ability to learn and refine its solutions iteratively,
- AIME: Zero-Shot CoT: 2.36% success rate (22 problems solved). MCTSr (8-rollouts): 11.79% success rate (110 problems solved).
- GAIC Math Odyssey: Zero-Shot CoT: 17.22% success rate (67 problems solved). MCTSr (8-rollouts): 49.36% success rate (192 problems solved).
- OlympiadBench: Zero-Shot CoT: 1.25% success rate (16 problems solved). MCTSr (8-rollouts): 7.76% success rate (99 problems solved).
Paper
Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B 2406.07394
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
