Papers Explained 161: Orca 2

Orca 2 continues exploring how improved training signals can enhance smaller LMs’ reasoning abilities. It aims to teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). Moreover, to help the model learn to determine the most effective solution strategy for each task.
Recommended Reading [Papers Explained 160: Orca]
Teaching Orca 2 to be a Cautious Reasoner
The key to Explanation Tuning is the extraction of answers with detailed explanations from LLMs based on system instructions. However, not every combination of system instruction cross tasks is appropriate, and in fact, the response quality can vary significantly based on the strategy described in the system instruction. Hence the strategy an LLM uses to reason about a task should depend on the task itself.
The study proposes the term Cautious Reasoning to refer to the act of deciding which solution strategy to choose for a given task — among direct answer generation, or one of many “Slow Thinking” strategies (step-by-step, guess and check or explain-then-answer, etc.).
The following illustrates the process of training a Cautious Reasoning LLM:
- Start with a collection of diverse tasks.
- Guided by the performance of Orca, decide which tasks require which solution strategy (e.g. direct-answer, step-by-step, explain-then-answer, etc.)
- Write task-specific system instruction(s) corresponding to the chosen strategy in order to obtain teacher responses for each task.
- Prompt Erasing: At training time, replace the student’s system instruction with a generic one vacated of details of how to approach the task.
Dataset Construction
For Orca 2, a new dataset with ~817K training instances is created, which is referred to as the Orca 2 dataset. Following Orca 1, Orca 2 has been trained with progressive learning, with subsets of data obtained from combining the original FLAN annotations, Orca 1 dataset and the Orca 2 dataset.
The Orca 2 dataset has four main sources:
FLAN: Following Orca 1 tasks only from CoT, NiV2, T0, Flan 2021 sub-collections are considered, which contain a total of 1913 tasks. For the Cautious-Reasoning FLAN dataset construction, ~602K zero-shot user queries are selected from the training split of 1448 high quality tasks out of the 1913 tasks, filtering many synthetically generated tasks. For alignment towards cautious reasoning, all the system instructions are replaced with the following generic system instruction:

Few Shot Data: A Few-Shot dataset consisting of 55K samples is created by re-purposing the zero-shot data from Orca 1 dataset.
Math: ~160K math problems are collected from the Deepmind Math dataset and the training splits of a collection of existing datasets: GSM8K, AquaRat, MATH, AMPS, FeasibilityQA, NumGLUE, AddSub, GenArith and Algebra.
Fully synthetic data: 2000 Doctor-Patient Conversations are synthetically created with GPT-4. Then the model is instructed to create a summary of the conversation with four sections: HISTORY OF PRESENT ILLNESS, PHYSICAL EXAM, RESULTS, ASSESSMENT AND PLAN. Two different prompts are used: one with high-level task instruction and another with detailed instructions that encourages the model to avoid omissions or fabrications. This data is used to assess the learning of specialized skills.
Training
Starting with the LLaMA-2–7B and LLaMA-2–13B checkpoints, the models are fine-tuned on the train split of the FLAN-v2 dataset for one epoch. The models are then trained on 5 million ChatGPT data from Orca 1 for three epochs. Then finally the models are trained on the combination of 1 million GPT-4 data from Orca 1 and 817K data from Orca 2 for four epochs.
The LLaMA Byte Pair Encoding (BPE) tokenizer is used for processing the input examples. Notably, the LLaMA tokenizer splits all numbers into individual digits, and fallbacks to bytes to decompose unknown UTF-8 characters. To deal with variable length sequences a padding token “[[PAD]]” is added into the LLaMA tokenizer vocabulary. The ChatML special tokens “<|im_start|>” and “<|im_end|>” are also added. The resulting vocabulary contains 32003 tokens.
To optimize the training process and utilize the available computational resources efficiently, packing technique is used with max_len= 4096 tokens.. This method involves concatenating multiple input examples into a single sequence, which is then used for training the model.I
For the purpose of training Orca 2, the loss is computed only on the tokens generated by the teacher model, i.e., it learns to generate responses conditioned on the system instruction and task instructions. This approach ensures that the model focuses on learning from the most relevant and informative tokens, improving the overall efficiency and effectiveness of the training process.
Evaluation
Reasoning
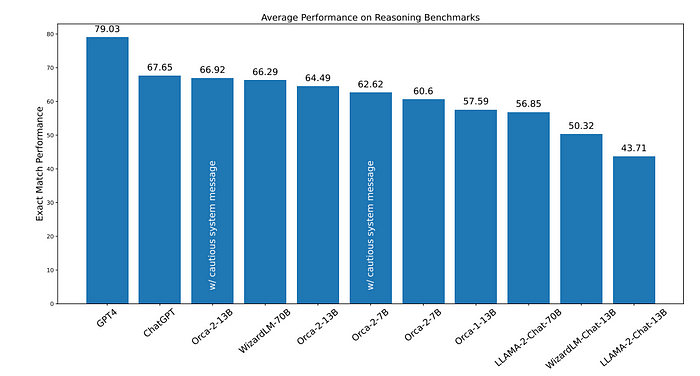
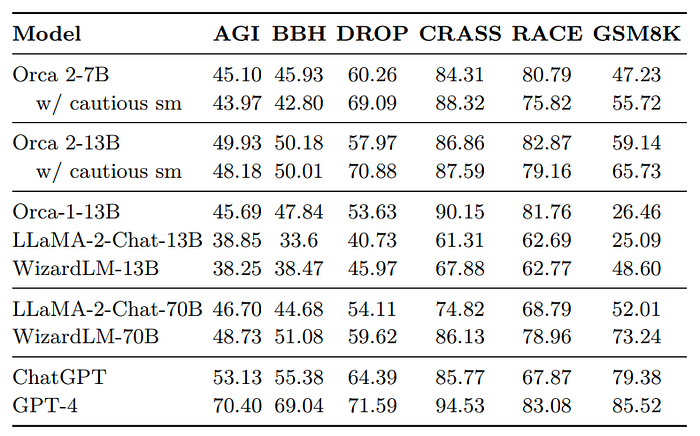
- Orca-2–13B significantly outperforms models of the same size on zero-shot reasoning tasks (47.54% relative improvement over LLaMA-2-Chat-13B, 28.15% over WizardLM-13B).
- Orca-2–13B exceeds the performance of LLaMA-2-Chat-70B and performs comparably to WizardLM-70B and ChatGPT.
- Orca-2–7B is better or comparable to LLaMA-2-Chat-70B on all reasoning tasks.
- Using the cautious system message with both 7B and 13B models provides small gains over the empty system message.
Knowledge and Language Understanding
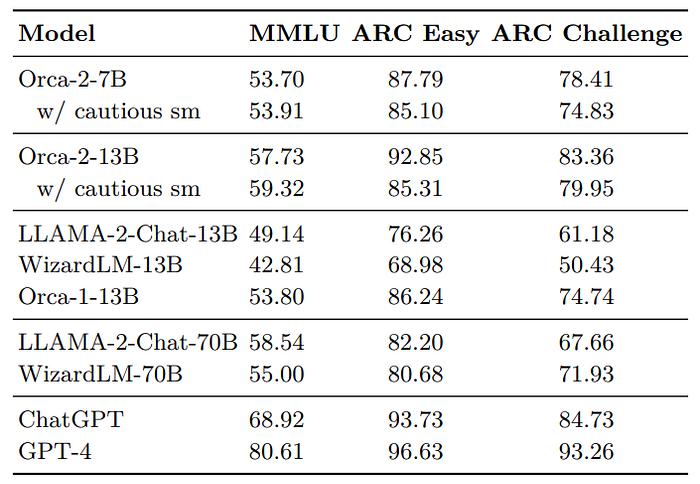
- Orca-2–13B surpasses LLaMA-2-Chat-13B and WizardLM-13B in individual benchmarks.
- Orca-2–13B achieves a relative improvement of 25.38% over LLaMA-2-Chat-13B and 44.22% over WizardLM-13B.
- Orca-2–13B performs similarly to 70B baseline models in MMLU benchmark (57.73% vs. 58.54%).
- Orca-2–7B surpasses both 70B baselines on ARC test set.
Text Completion
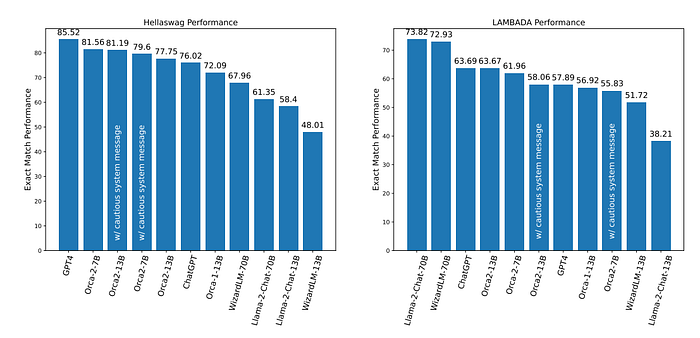
- Orca-2–7B and Orca-2–13B exhibit strong performance on HellaSwag, outperforming baselines.
- GPT-4’s performance in LAMBADA task is subpar, often claiming insufficient context or proposing incorrect answers.
Multi-Turn Open Ended Conversations
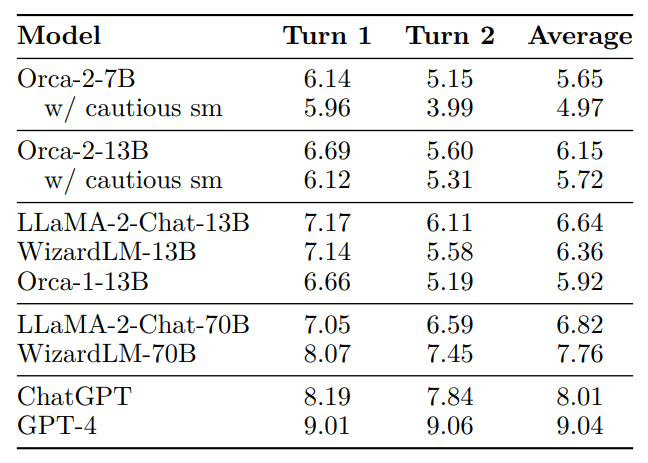
- Orca-2–13B performs comparably with other 13B models.
- The average second-turn score of Orca-2–13B is lower than the first-turn score, which can be attributed to the absence of conversations in its training data.
- Orca 2 is capable of engaging in conversations and can be enhanced by packing multiple zero-shot examples into the same input sequence.
Grounding
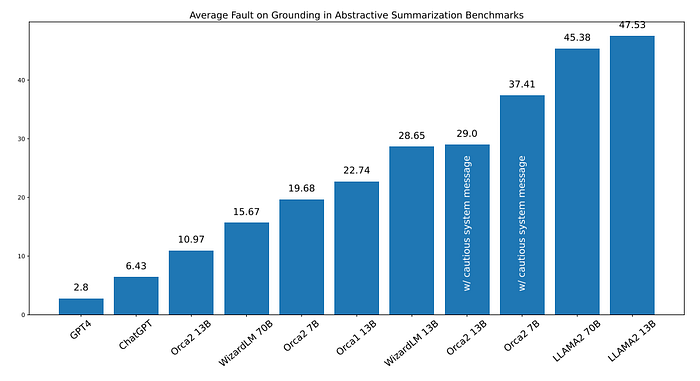
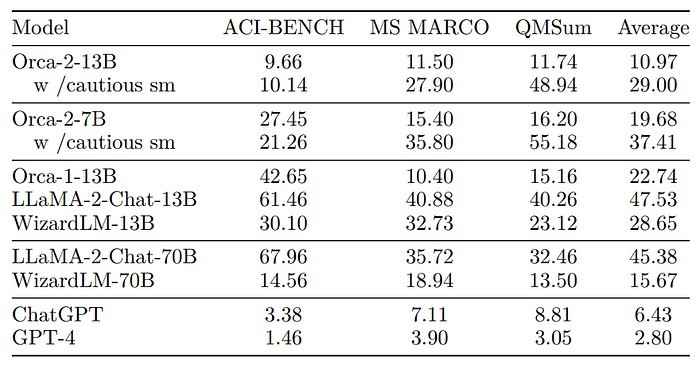
- Orca-2–13B exhibits the lowest rate of hallucination among all Orca 2 variants and other 13B and 70B LLMs.
- Compared to LLaMA-2–13B and WizardLM-13B models, Orca-2–13B demonstrates a relative reduction of 76.92% and 61.71% in hallucination rate.
Paper
Orca 2: Teaching Small Language Models How to Reason 2311.11045
Recommended Reading [Orca Series] [Small LLMs]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!