Papers Explained 151: Aya 23

Aya 23 is a family of multilingual language models that can serve 23 languages. It is an improvement over the previous model, Aya 101, which covered 101 languages but had limitations due to the “curse of multilinguality”. Aya 23 balances breadth and depth by allocating more capacity to fewer languages, resulting in better performance on the languages it covers.
Aya 23 is available in two sizes 8B and 35B.

Pretrained Models
The Aya 23 model family is based on the Cohere Command series models. The model uses a standard decoder-only Transformer architecture with several modifications to improve training efficiency and performance. These modifications include:
- Parallel Attention and FFN layers, which improve training efficiency without hurting model quality.
- SwiGLU activation, which has been found to have higher downstream performance than other activations.
- No bias in dense layers, which improves training stability.
- Rotary positional embeddings (RoPE), which provide better long context extrapolation and short context performance.
- A BPE tokenizer with a size of 256k, which is trained on a subset of pre-training datasets to ensure efficient representations across languages.
- Grouped Query Attention (GQA), which reduces inference-time memory footprint by sharing multiple Q heads with each KV head.

The Aya-23–35B model is essentially a further fine-tuned version of Cohere Command R.
Instruction Fine Tuning
The multilingual instruction data described in the Aya 101 model is adopted for fine tuning the Aya 23 models:
- Multilingual Templates: Structured text is used to transform specific NLP datasets into instruction and response pairs. This collection, consisting of 55.7M examples, is derived from the xP3x dataset, the data provenance collection, and the Aya collection, covering 23 languages and 161 different datasets.
- Human Annotations: The Aya dataset has a total of 204K human-curated prompt-response pairs written by native speakers in 65 languages. After filtering for the 23 languages being trained on, this data results in 55K samples.
- Translated Data: The translated subset of the Aya collection is used, which includes translations of widely used English instruction datasets. This collection includes translations of HotpotQA and Flan-CoT-submix, among others. A random subset of up to 3,000 instances for each language for each dataset is preserved to maintain instance-level diversity. After filtering for the 23 languages being trained on, this data results in a subset of 1.1M examples.
- Synthetic Data: Synthetic fine-tuning data is constructed using human-annotated prompts from ShareGPT5 and Dolly-15k. Unlike previous methods, this data uses Cohere’s Command R+ to natively generate multilingual responses for the translated ShareGPT and Dolly prompts in all 23 languages, resulting in 1.63M examples.
The models are finetuned using an 8192 context length with data packing enabled.
Similar to other instruction-tuned models, the examples used to instruction-tune Aya 23 are formatted using special tokens to include extra information:

Evaluation
Discriminative Tasks
Models are tested on zero-shot evaluation for completely unseen tasks such as XWinograd, XCOPA, and XStoryCloze.
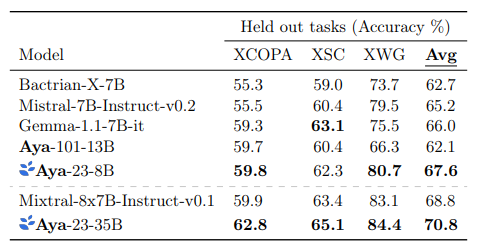
- Aya-23–35B outperforms all baselines with an average accuracy of 70.8% across the tasks and languages.
- Aya-23–35B shows a slight edge over Mixtral-8x7B-Instruct-v0.1 (70.8 vs 68.8), which is another large model.
- Aya-23–8B, within its class of models of similar size, achieves the best score with an average accuracy of 67.6%, outperforming other models like Gemma-1.1–7B-it (66.0), Bactrian-X-7B, Mixtral-7B-Inst-v0.2, and Aya-101–13B.12.
General Language Understanding
Models are evaluated on the Multilingual MMLU dataset for language understanding across 14 languages.
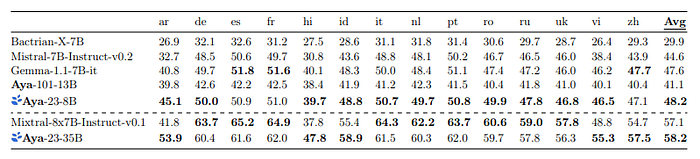
- Aya-23–8B achieves an average accuracy of 48.2% across all languages and is the top performer in 11 out of 14 languages.
- Aya-23–35B outperforms Mixtral-8x7B-Inst with an average accuracy of 58.2% compared to Mixtral’s 57.1%.
- Mixtral-8x7B-Inst performs slightly better in high-resource European languages but underperforms relative to Aya-23–35B in non-European languages such as Arabic, Hindi, and Vietnamese.
- For Arabic, Hindi, and Vietnamese, Aya-23–35B shows a significant improvement over Mixtral-8x7B-Inst with accuracy increases of 12.1%, 10.0%, and 6.5% respectively.
Mathematical Reasoning
Models are assessed on the Multilingual Grade School Math (MGSM) Benchmark for mathematical reasoning in 10 languages.
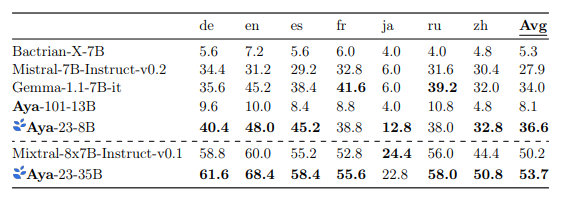
- Aya-23–8B, outperformed all other in-class baselines, with a score of 36.6 across the seven languages.
- Gemma-1.1–7b was the next best model in its class with a score of 34.0.
- Aya-23–8B showed a 4.5x increase in performance compared to Aya-101–13B (36.6 vs 8.1), indicating the significant impact of using a high-quality pre-trained model.
- Aya-23–35B outperformed Mixtral-8x7B-Instruct-v0.1 with a score of 53.7, demonstrating the benefits of larger scale models.
- Aya-23 models were superior to their in-class counterparts for six languages (English, Spanish, German, Chinese, and Arabic) but had comparable performance to the best in-class models for French, Russian, and Japanese.
Generative Tasks
Performance on machine translation and summarization is evaluated using FLORES-200 and XLSum datasets, respectively, in 21 and 15 languages.
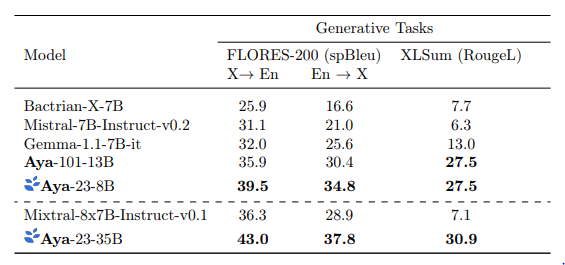
- Aya-23–8B achieved an average spBleu score of 37.2 in FLORES translation tasks, outperforming the second best model, Aya-101–13B, by 4 points.
- In XLSum multilingual summarization tasks, both Aya-23–8B and Aya-101–13B achieved an average RougeL score of 27.5, surpassing Gemma-1.1 by 14.5 points.
- Aya-23–35B outperformed Mixtral-8x7B by 7.8 spBleu (40.4 vs 32.6) in translation tasks and by 23.8 (30.9 vs 7.1) in summarization tasks.
Preference Evaluation
Models are evaluated on their ability to generate preferred responses in open-ended scenarios using both LLM-simulated win-rates and human evaluation. This includes using GPT-4 as a proxy judge and human annotators for preference selection.

- Aya-23–8B outperforms other models like Aya-101–13B, Mistral-7B-Instruct-v0.2, and Gemma-1.1–7B-it with an average win rate of 82.4%.
- Aya-23–35B outperforms Mixtral-8x7B-Instruct-v0.1 with an average win rate of 60.9%.
- Aya 23 models achieve superior win rates across all languages, except for specific cases in English, French, and Spanish against the baseline models.
- For non-European languages like Turkish, Hindi, and Japanese, Aya 23 models outperform comparison models by a significant margin.
- Aya-23–8B is heavily preferred over Aya-101–13B in all 10 languages for human evaluation, with Aya-23–8B winning against Aya-101–13B for 50.8% of prompts on average across languages.
- Aya-23–35B achieves a 57.6% win rate against Aya-101–13B in human evaluation.
Safety, Toxicity & Bias
Models are evaluated for safety, toxicity, and bias using the multilingual AdvBench and identity description prompts. GPT-4 is used as an automatic evaluator for harmfulness, and Perspective API measures toxicity and bias.


- The Aya 23 models (both 13B and 35B) showed a reduced rate of harmful responses compared to the Aya-101–13B model across all languages, with an average reduction of at least half.
- The Aya-23–35B model demonstrated even lower harmfulness, particularly for Arabic and Italian, attributed to improved cross-lingual transfer capabilities.
- In terms of quality, the refusal responses generated by the Aya 23 models were found to be more eloquent, diverse, and elaborate than those from the Aya-101–13B model.
- The Aya 23 models generally had lower expected maximum toxicity and a lower toxicity probability than the Aya-101–13B model, except for English where toxicity was slightly higher.
- While Aya 23 models produced less toxic descriptions for Asians and Latinx, they had a higher chance of producing toxic descriptions for Blacks and Whites, particularly for women.
Aya Expanse
Aya Expanse is a family of highly performant multilingual models that excels across 23 languages and outperforms other leading open-weight models. The 8 billion parameters model makes breakthroughs more accessible to researchers worldwide, and the 32 billion parameters model offers state-of-the-art multilingual capabilities.
The models are available at HuggingFace.
The use of synthetic data has become increasingly central to the development of LLMs, particularly as model training has exhausted data sources. However, for multilingual data, especially with languages that are low-resource, there are few good examples of teacher models, creating an extra challenge to leveraging synthetic data.
A novel data sampling strategy is proposed, termed data arbitrage, to avoid mode collapse, or the generation of “gibberish” when over relying on synthetic data. Data arbitrage takes inspiration from how humans learn by going to different teachers for different skills.
Preference training is used in the late stages of model training, leveraging feedback from humans to guide the model toward what high-quality outputs look like. However, preference training and safety measures often overfit to harms prevalent in Western-centric datasets.
The work extended preference training to a massively multilingual setting, accounting for different cultural and linguistic perspectives. The final step to the breakthrough in multilingual performance is work on model merging — combining the weights of multiple candidate models at each stage to create more versatility and performance.
All these techniques are combined in one training recipe for Aya Expanse. Each of these techniques — from data arbitrage to merging and multilingual preference optimization — enabled step-by-step improvement, leading to a significant gain against other leading models in the same parameter classes.
Evaluation
- Aya Expanse 32B outperforms Gemma 2 27B, Mistral 8x22B, and Llama 3.1 70B, a model more than 2x its size, setting a new state-of-the-art for multilingual performance.
- Aya Expanse 8B, outperforms the leading open-weights models in its parameter class such as Gemma 2 9B, Llama 3.1 8B, and the recently released Ministral 8B with win rates ranging from 60.4% to 70.6%.
Paper
Aya 23: Open Weight Releases to Further Multilingual Progress
Aya Expanse: Connecting Our World
Recommended Reading [Aya Series]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
