Papers Explained 137: LongLLMLingua

LongLLMLingua is a framework designed for prompt compression in long context scenarios. It addresses three main challenges associated with LLMs in long context scenarios: higher computational/financial cost, longer latency, and inferior performance. LongLLMLingua achieves this through a series of innovative strategies:
- Question-Aware Coarse-to-Fine Compression, to improve the density of information relevant to the question in the prompt by evaluating the tokens within the documents.
- Document Reordering Mechanism, to mitigate the issue of information loss in the middle of long contexts.
- Dynamic Compression Ratios, for adaptive granular control during compression to documents based on their relevance to the question.
- Post-Compression Sub-sequence Recovery Strategy, to improve the integrity of key information.
The project is available at llmlingua.com.
Recommended Reading [Papers Explained 136: LLMLingua]
Problem Formulation
The objective is to extend the LLMLingua objective to scenarios specially dealing with prompts that include instructions, multiple documents, and a question.

- x~ is the compressed version of the original prompt ( x ).
- (D(y, y~ ) is a measure of how different the output from the LLM is when using the compressed prompt compared to the output when using the original prompt. This difference is quantified using a distance measure like KL divergence.
- λ is a parameter that helps balance between making the prompt as short as possible and keeping the LLM’s output as close as possible to what it would be with the original prompt.
- ( |x~|_0 ) represents the length of the compressed prompt, specifically counting the number of tokens it contains.
Method

How to improve key information density in the prompt
Question-Aware Coarse-Grained Compression
In coarse grained compression, the documents which contain the information most relevant to the question at hand are determined by calculating a metric, denoted as (r_k), for each document.
r_k is calculated using document-level perplexity, which is a measure of how well the content of a document is predicted by the model. The idea is that documents with lower perplexity (i.e., those that the model predicts more accurately) are considered more important.

where x que,restrict i is the i-th token in the concatenated sequence of x que and x restrict and Nc in the number of tokens, and x restrict = “We can get the answer to this question in the given documents”.
Question-Aware Fine-Grained Compression
In fine-grained compression, the importance of each token in the instruction x ins, the question x que, and K′ retained documents x doc iis assessed.
The iterative compression mechanism following LLMLingua is incorporated and token perplexities are directly calculated to compress x ins and x que.
A straightforward solution to make the fine-grained token-level compression over the documents aware of the question is to simply concatenate it at the beginning of the whole context. However, this will result in low perplexities of relevant tokens in the context following the condition, further reducing their differentiation from general tokens. Hence contrastive perplexity, i.e., the distribution shift caused by the condition of the question, is used to represent the association between the token and the question.
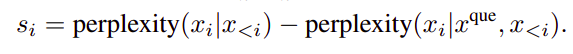
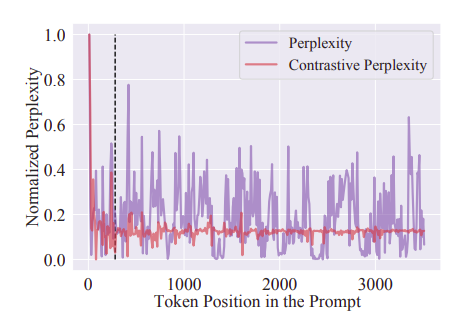
It can be seen that tokens of high perplexities are widely distributed in all documents. However, tokens with high contrastive perplexities concentrate more on the left side of the dashed line, which corresponds to the document that contains the answer to the question. This suggests that the proposed contrastive perplexity can better distinguish tokens relevant to the question, thus improving the key information density in the compressed results.
How to reduce information loss in the middle
LLM achieves the highest performance when relevant information occurs at the beginning and significantly degrades if relevant information is located in the middle of long contexts.
Therefore, the documents are reordered using their importance scores to better leverage LLMs’ information perception difference in positions:
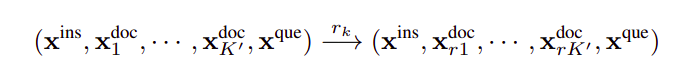
How to achieve adaptive granular control during compression
Coarse-grained compression is bridged to fine-grained compression using the importance scores r_k to guide the budget allocation for each document based in the key information density present in it.
Firstly, the initial budget τ doc (τ dems in llm lingua) is determined for the retained documents using the budget controller of LLMLingua. Then the iterative token-level compression algorithm in LLMLingua is followed but with dynamically assigned compression budget τ doc_k for each document x doc_k according to the ranking index I(r_k).
A linear scheduler is used for the adaptive allocation. Budget of each token xi can be formulated as:
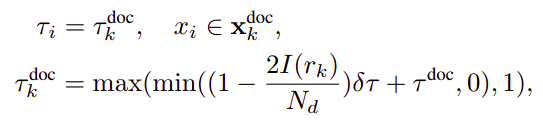
where Nd denotes the number of documents, and δτ is a hyper-parameter that controls the overall budget for dynamic allocation.
How to improve the integrity of key information

Certain tokens of key entities may be discarded during the fine-grained token-wise compression. The sub-sequence recovery method relies on the sub-sequence relationship among tokens in the original prompt, compressed prompt, and LLMs’ response.

Evaluation
Datasets Used: NaturalQuestions, LongBench, and ZeroSCROLLS.
Baselines: Retrieval-based Methods (BM25, Gzip, Sentence-BERT, OpenAI Embedding) and Compression-based Methods (Selective Context, LLMLingua).
Target LLMs: GPT-3.5-Turbo-06134 and LongChat-13B-16k.
Compression Models: LLaMA-2–7B-Chat for small language models.
Effectiveness of LongLLMLingua
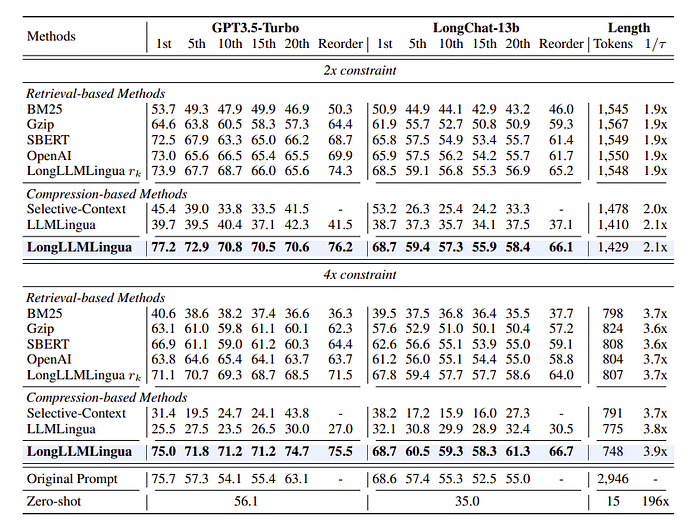
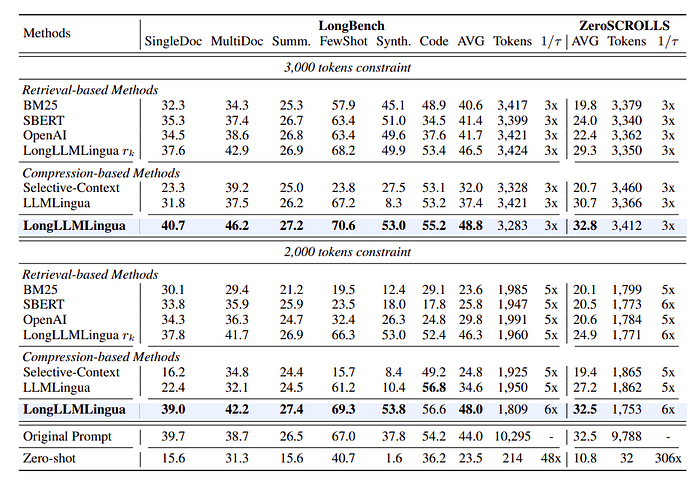
- LongLLMLingua achieves superior performance across various tasks and compression constraints.
- Demonstrates higher performance with significantly reduced input token count.
Efficiency of LongLLMLingua
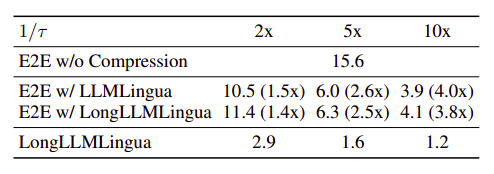
- Significant reduction in latency, especially as the compression rate increases.
- The prompt compression system accelerates overall inference, with more pronounced effects in scenarios with longer API cost time.
Ablation Study of LongLLMLingua Components
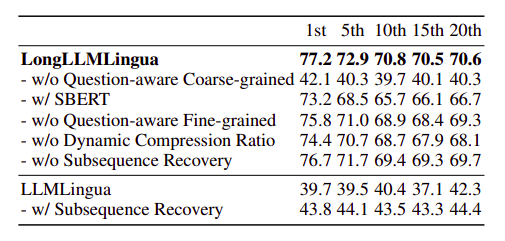
- Removing any component from LongLLMLingua leads to a performance drop.
- Validates the necessity and effectiveness of the question-aware mechanism, dynamic compression ratio, and subsequence recovery strategy.
- SBERT for coarse-grained compression results in inferior performance compared to the question-aware importance metric.
Paper
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression 2310.06839
Recommended Reading [LLM Lingua Series]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
