Papers Explained 135: DSPy

DSPy is a programming model designed to improve how language models (LMs) are used in complex tasks. Traditionally, LMs are controlled using fixed prompt templates, which are basically pre-set instructions found through a lot of trial and error. DSPy changes this by abstracting LM pipelines as text transformation graphs, i.e. imperative (specifies and directs the control flow of the program) computation graphs where LMs are invoked through declarative modules (specifies the expected result and core logic without directing the program’s control flow).
DSPy is available at https://github.com/stanfordnlp/dspy.
The DSPy Programming Model
The DSPy programming model first translates string-based prompting techniques, including complex and task-dependent ones like Chain of Thought and ReAct into declarative modules that carry natural-language typed signatures.
DSPy modules are task-adaptive components — similar to neural network layers — that abstract any particular text transformation, like answering a question or summarizing a paper. Each module is parameterized so that it can learn its desired behavior by iteratively bootstrapping useful demonstrations within the pipeline.
The DSPy compiler optimizes any DSPy program to improve quality or cost. The compiler inputs are the program, a few training inputs with optional labels, and a validation metric.
The compiler simulates versions of the program on the inputs and bootstraps example traces of each module for self-improvement, using them to construct effective few-shot prompts or fine tuning small LMs for steps of the pipeline. Optimization in DSPy is highly modular: it is conducted by teleprompters,which are general-purpose optimization strategies that determine how the modules should learn from data. In this way, the compiler automatically maps the declarative modules to high-quality compositions of prompting, finetuning, reasoning, and augmentation.
DSPy contributes three abstractions toward automatic optimization: signatures, modules, and teleprompters.
- Signatures abstract the input/output behavior of a module
- Modules replace existing hand-prompting techniques and can be composed in arbitrary pipelines
- Teleprompter optimizes all modules in the pipeline to maximize a metric.
DSPy Signatures
DSPy signatures are declarative specifications that define the input/output behavior of modules within the DSPy programming model. These signatures are used to specify what a task needs to do, rather than how to prompt a language model (LM) to perform the task. This approach abstracts the prompting and fine-tuning process, making it more modular and less prone to errors associated with free-form string manipulation.
Inline DSPy Signatures: Inline signatures are concise and defined using a simple string format that specifies the semantic roles of inputs and outputs. For example:
qa = dspy . Predict (" question -> answer ")
qa ( question ="What is the capital of India?")These signatures are straightforward and are used directly in DSPy modules like dspy.Predict to perform specific tasks. The field names in these signatures are semantically meaningful and guide the DSPy system in processing the inputs and outputs appropriately.
Class-based DSPy Signatures: Class-based signatures are more verbose and are used for complex tasks that require additional specifications about the inputs and outputs. These signatures can include:
- Docstrings that describe the task.
- Descriptive keywords for input and output fields to provide more context or constraints.
class Emotion(dspy.Signature):
"""Classify emotion among sadness, joy, love, anger, fear, surprise."""
sentence = dspy.InputField()
sentiment = dspy.OutputField()
sentence = "i started feeling a little vulnerable when the giant spotlight started blinding me" # from dair-ai/emotion
classify = dspy.Predict(Emotion)
classify(sentence=sentence)Class-based signatures are particularly useful when tasks need clear definitions and when optimizing the prompting process to achieve better performance across different LMs.
DSPy Modules
DSPy modules are building blocks for programs that utilize LMs to perform various tasks. Each module in DSPy is parameterized, meaning it has learnable parameters that include the specifics of the prompt, the language model to be used, and the demonstrations for prompting or training. They process inputs according to a defined “signature” and return outputs based on that processing.
There are various types of modules, each abstracting different prompting techniques:
dspy.Predict: Basic predictor. Does not modify the signature. Handles the key forms of learning (i.e., storing the instructions and demonstrations and updates to the LM).dspy.ChainOfThought: Teaches the LM to think step-by-step before committing to the signature's response.dspy.ProgramOfThought: Teaches the LM to output code, whose execution results will dictate the response.dspy.ReAct: An agent that can use tools to implement the given signature.dspy.MultiChainComparison: Can compare multiple outputs fromChainOfThoughtto produce a final prediction.
These modules abstract prompting techniques and are designed to be flexible and modular, allowing them to be composed into larger, more complex systems.
import dspy
class RAG(dspy.Module):
def __init__(self, num_passages=3):
# 'Retrieve' will use the user's default retrieval settings unless overridden.
self.retrieve = dspy.Retrieve(k=num_passages)
# 'ChainOfThought' with signature that generates answers given retrieval & question.
self.generate_answer = dspy.ChainOfThought("context, question -> answer")
def forward(self, question):
context = self.retrieve(question).passages
return self.generate_answer(context=context, question=question)DSPy Teleprompters (Optimizers)
DSPy optimizers, formerly known as teleprompters, are algorithms that can tune the parameters of a DSPy program (i.e., the prompts and/or the LM weights) to maximize the metrics you specify, like accuracy.
A typical DSPy optimizer takes three things:
- A DSPy program. This may be a single module (e.g.,
dspy.Predict) or a complex multi-module program. - A metric. This is a function that evaluates the output of your program, and assigns it a score (higher is better).
- A few training inputs. This may be very small and incomplete (only inputs without any labels).
DSPy programs consist of multiple calls to LMs, stacked together as [DSPy modules]. Each DSPy module has internal parameters of three kinds: (1) the LM weights, (2) the instructions, and (3) demonstrations of the input/output behavior.
Given a metric, DSPy can optimize all of these three with multi-stage optimization algorithms. These can combine gradient descent (for LM weights) and discrete LM-driven optimization, i.e. for crafting/updating instructions and for creating/validating demonstrations.
DSPy Demonstrations are like few-shot examples, but they’re far more powerful. They can be created from scratch, given the program, and their creation and selection can be optimized in many effective ways.
There are several types of DSPy optimizers available, each suited for different scenarios and data availability:
Automatic Few-Shot Learning
LabeledFewShot: Constructs few-shot examples from provided labeled question/answer pairs.BootstrapFewShot: Generates complete demonstrations for every stage of the program using the program itself, without further optimization unless the demonstrations meet the metric criteria. (Preferred if very little data, e.g. 10 examples are available).BootstrapFewShotWithRandomSearch: Repeats the BootstrapFewShot process several times with random variations, selecting the best outcome. (Preferred if slightly more data, e.g. 50 examples are available).BootstrapFewShotWithOptuna: Uses Optuna for hyperparameter optimization across demonstration sets to maximize evaluation metrics.
Automatic Instruction Optimization
COPRO: Focuses on generating and refining new instructions for each step and optimizes them using coordinate ascent.MIPRO: Generates instructions and few-shot examples that are data-aware and demonstration-aware, using Bayesian Optimization for effective searching. (Preferred if good amount of data, e.g. 300examples are available).
Automatic Finetuning
BootstrapFinetune: Converts a prompt-based DSPy program into one where each step is conducted by a finetuned model rather than a prompted LM.
Program Transformations
KNNFewShot: Integrates the k-Nearest Neighbors algorithm with BootstrapFewShot for demonstration selection.Ensemble: Combines multiple DSPy programs into a single program, either using the full set or a subset sampled randomly.
DSPy Compiler
The DSPy compiler automatically optimizes any program within its programming model, enhancing the quality or cost of modules through prompting or finetuning.
he DSPy compiler operates through three main stages:
- Candidate Generation: In this initial stage, the compiler identifies all unique Predict modules (predictors) within a program, including those nested within other modules. For each predictor, the teleprompter may generate candidate values for various parameters such as instructions, field descriptions, and demonstrations (example input-output pairs). Demonstrations are particularly emphasized, and simple rejection-sampling-like methods are used to bootstrap effective multi-stage systems. This stage involves simulating a teacher program or the zero-shot version of the program on training inputs to generate potential labels and demonstrations from good examples.
- Parameter Optimization: Each parameter identified in the first stage now has a set of candidate values. Various hyperparameter tuning algorithms, such as random search or Tree-structured Parzen Estimators, are applied to select the best candidates. Additionally, finetuning may be used where demonstrations update the language model’s (LM) weights for each predictor, optimizing the average quality using the program’s metric with cross-validation over the training or validation set.
- Higher-Order Program Optimization: The final stage involves modifying the control flow of the program. One common method used is ensembles, where multiple copies of the same program are bootstrapped and then combined into a new program that runs them in parallel, integrating their predictions through a custom function like majority voting. This stage allows for more dynamic optimizations and can incorporate techniques like test-time bootstrapping and automatic backtracking-like logic.
from dspy.teleprompt import BootstrapFewShotWithRandomSearch
# Set up the optimizer: we want to "bootstrap" (i.e., self-generate)
# 8-shot examples of your program's steps.
# The optimizer will repeat this 10 times (plus some initial attempts)
# before selecting its best attempt on the devset.
config = dict(
max_bootstrapped_demos=3, max_labeled_demos=3,
num_candidate_programs=10, num_threads=4
)
teleprompter = BootstrapFewShotWithRandomSearch(
metric=YOUR_METRIC_HERE, **config
)
optimized_program = teleprompter.compile(
YOUR_PROGRAM_HERE, trainset=YOUR_TRAINSET_HERE
)Evaluation
The evaluations seek to test the following hypotheses:
H1 With DSPy, we can replace hand-crafted prompt strings with concise and well-defined modules, without reducing quality or expressive power.
H2 Parameterizing the modules and treating prompting as an optimization problem makes DSPy better at adapting to different LMs, and it may outperform expert-written prompts.
H3 The resulting modularity makes it possible to more thoroughly explore complex pipelines that have useful performance characteristics or that fit nuanced metrics.
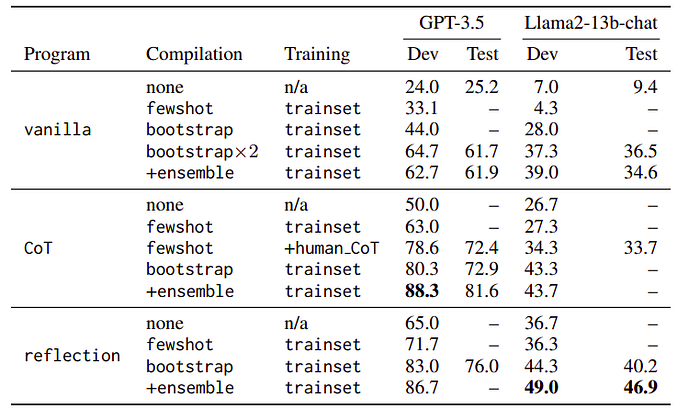
- Compiling the correct modules, instead of string prompts, improves different LMs from 4–20% accuracy to 49–88% accuracy.
DSPy in Action
Here is an example how we can use DSPy to optimise prompts in existing production grade langchain applications:
Paper
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines 2310.03714
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
