Papers Explained 132: RecurrentGemma

RecurrentGemma-2B is an open model based on the Griffin architecture. It uses a combination of linear recurrences and local attention instead of global attention.
The project is available at GitHub.
The models are available at HuggingFace.
Recommended Reading [Papers Explained 131: Hawk, Griffin]
Architecture
One single modification is made to the Griffin architecture, which is to multiply the input embeddings by a constant equal to the square root of model width. The input and output embeddings are tied, but this factor is not applied to the output.
A similar multiplicative factor appears in Gemma as well.

Training
Pre training
Recurrent Gemma is trained on sequences of 8192 tokens of the same pre-training data as Gemma-2B, which comprises primarily English data from web documents, mathematics and code.
RecurrentGemma-2B is trained on 2T tokens as compared to 3T tokens in case of Gemma-2B.
Like Gemma, a subset of the SentencePiece tokenizer, with a vocabulary size of 256k tokens is used.
Instruction turing and RLHF
A similar instruction tuning approach to Gemma, including a novel RLHF algorithm to fine-tune the model to output responses with high reward is followed.

Evaluation
Automated Benchmarks

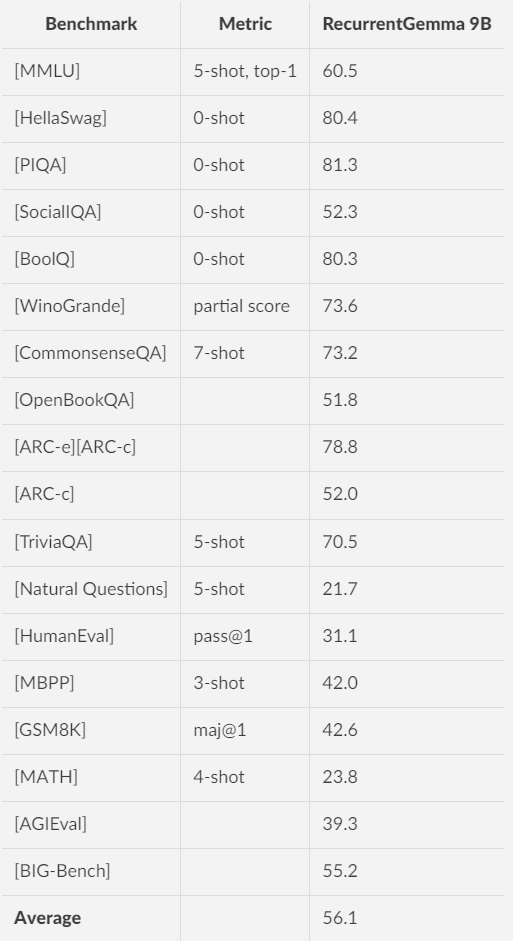
- RecurrentGemma-2B shows comparable performance to Gemma-2B, despite being trained on 50% fewer tokens.
Human Evaluation
Human evaluation with a held-out collection of prompts (1000 for creative and coding tasks, 400 for safety protocols).
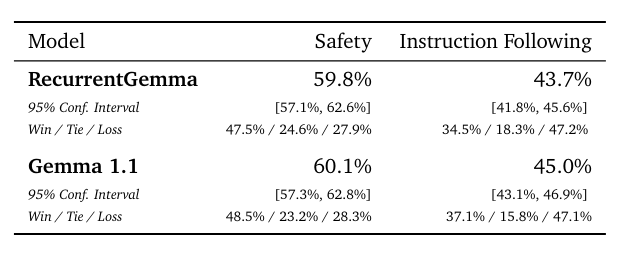
- RecurrentGemma-2B-IT achieves a 43.7% win rate in creative and coding tasks, slightly below Gemma-1.1–2B-IT’s 45.0%.
- Demonstrates competitive performance despite the smaller model size.
Model Safety and Responsible Deployment
Evaluation on standard academic safety benchmarks and Independent ethics and safety evaluations.
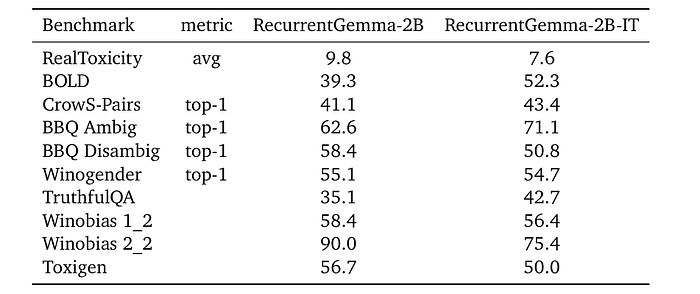
- RecurrentGemma meets safety benchmarks with improved scores in instruction-tuned variants.
RecurrentGemma 9B
Automated Benchmarks
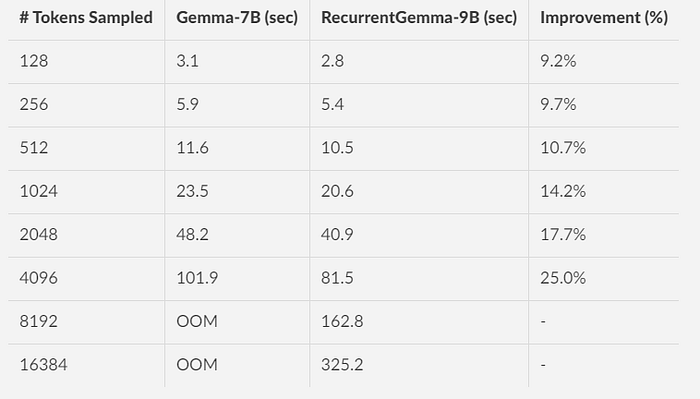
Inference Speed Results
The throughput is evaluated as the maximum number of tokens produced per second by increasing the batch size, of RecurrentGemma-9B compared to Gemma-7B, using a prefill of 2K tokens.
- RecurrentGemma provides improved sampling speeds, particularly for long sequences or large batch sizes.
End-to-end speedups achieved by RecurrentGemma-9B are comparedover Gemma-7B when sampling a long sequence after a prefill of 4K tokens and using a batch size of 1.
Paper
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models 2404.07839
Recommended Reading [Beyond Transformers] [Gemini / Gemma Models]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
