Papers Explained 124: CodeGemma

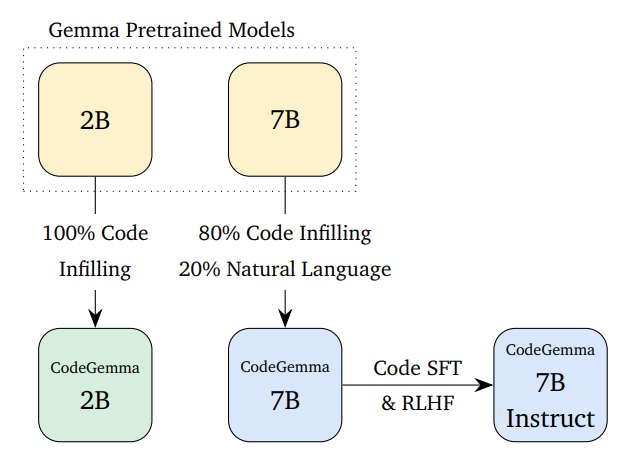
CodeGemma is a collection of open code models built on top of Gemma by further training on more than 500 billion tokens of code, capable of a variety of code and natural language generation tasks.
A 7B code pretrained model and a 7B instruction-tuned code model are released. Further, a specialized 2B model, trained specifically for code infilling and open-ended generation is also released.
Recommended Reading [Papers Explained 106: Gemma]
Pretraining
Training Data
The 2B models are trained with 100% code while the 7B models are trained with a 80% code, 20% natural language mixture.
The code corpus comes from publicly available code repositories. Datasets are deduplicated and filtered to remove contamination of evaluation code and certain personal and sensitive data.
Preprocessing for Fill-in-the-Middle
The pre-trained CodeGemma models are trained using a method based on the fill-in-the-middle (FIM) task. The models are trained to work with both PSM (Prefix-Suffix-Middle) and SPM (Suffix-Prefix-Middle) modes.

Multi-file Packing
As downstream code-related tasks may involve generating code based on a repository-level context as opposed to a single file, training examples are created by co-locating the most relevant source files within code repositories and best-effort grouping them into the same training examples.
The dependency graph is constructed by grouping files by repository. For each source file, imports are extracted from the top N lines and suffix matching is performed to determine the longest matching paths within the repository structure. Edge importance (a heuristic measure) between files is determined, and unimportant edges are removed to break cyclic dependencies (common in Python). All-pairs shortest paths within the graph are then calculated, where shorter distances signify stronger file relationships. Finally, the graph of files is linearized using a topological sort, with the next unparented node selected based on minimum distance to sorted nodes and ties broken using lexicographic order.
Files not covered by this dependency graph method are sorted alphabetically within their repository with unit tests packed next to their implementations.
Instruction Tuning
Mathematics Datasets
To enhance the mathematical reasoning capabilities of coding models, supervised finetuning is performed on a diverse set of mathematics datasets, including MATH, GSM8k, MathQA and a programmatically-generated dataset of algebraic problems.
The training experiments indicate that these datasets significantly boost code generation performance.
Coding Dataset
Synthetic code instruction data generation is used to create datasets for the supervised fine tuning (SFT) and reinforcement learning from human feedback (RLHF) phase.
A set of self-contained question-answer pairs is generated and then filtered using an LLM tasked with evaluating the helpfulness and correctness of the generated question-answer pairs.
Evaluation

Infilling Capability
To assess the code completion capabilities of CodeGemma models using single-line and multi-line settings and Validate the infilling abilities of CodeGemma in real-world scenarios with code dependencies.
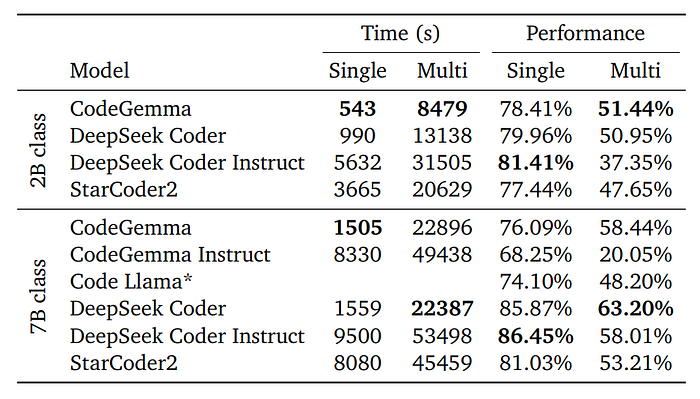
- CodeGemma’s 2B pretrained model performs comparably to other models but with nearly twice the speed during inference.
- Attributes performance enhancement to the architectural decisions of the base Gemma model.
Python Coding Capability
Evaluation of the performance of CodeGemma on canonical coding benchmarks.
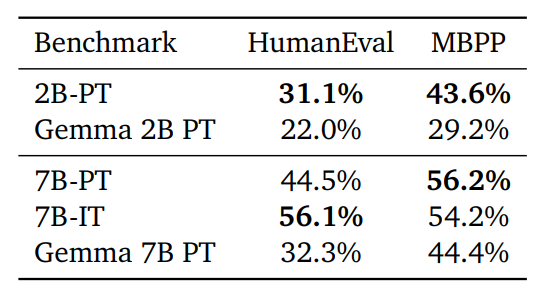
- CodeGemma models significantly outperform base Gemma models on coding tasks.
Multi-lingual Coding Benchmarks
Assessed the code generation performance of CodeGemma across various programming languages.
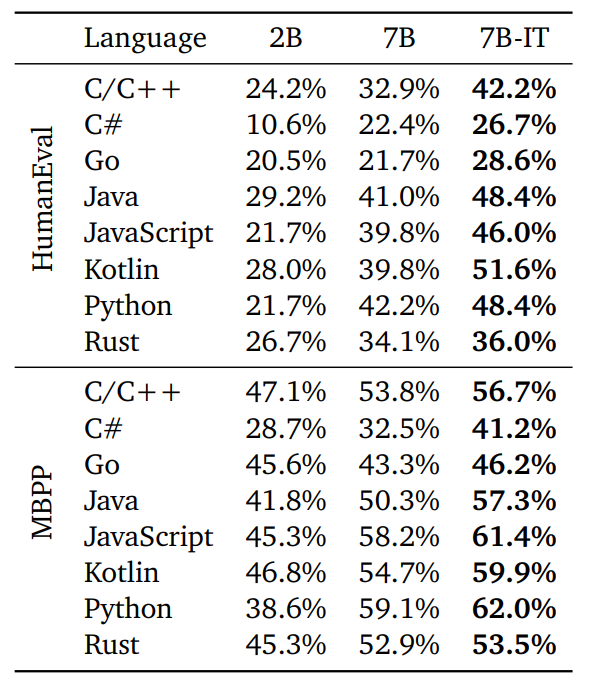
- CodeGemma shows strong performance across multiple languages, particularly in instruction-tuned versions.
Language Capability
Assessed the natural language understanding and mathematical reasoning capabilities of CodeGemma.
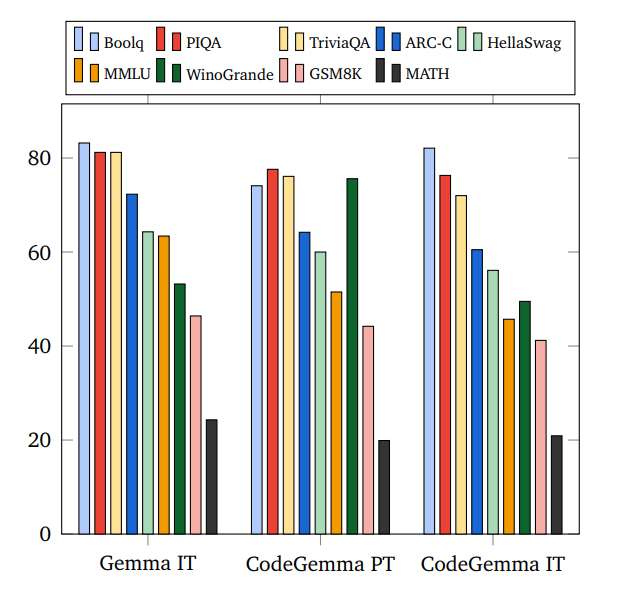
- CodeGemma shows strong performance across multiple languages, particularly in instruction-tuned versions.
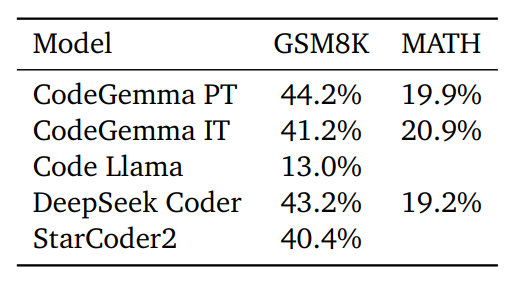
- CodeGemma excels at mathematical reasoning compared to similarly sized models.
Paper
CodeGemma: Open Code Models Based on Gemma
Recommended Reading [Gemini / Gemma Models] [LLMs for Code] [Small LLMs]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
