Papers Explained 118: WRAP

WRAP (Web Rephrase Augmented Pre-training) addresses challenges related to data curation, limited data availability, and computational efficiency in pre-training LLMs. It involves using an off-the-shelf instruction-tuned model prompted to paraphrase documents on the web in specific styles such as “like Wikipedia” or in “question-answer format” to jointly pre-train Large Language Models (LLMs) on real and synthetic rephrases. By rephrasing documents from the web into different styles, WRAP allows models to learn more efficiently and achieve performance gains on out-of-distribution datasets.
Recommended Reading [Papers Explained 114: Phi-1] [Papers Explained 115: Phi-1.5] [Papers Explained 116: Phi-2]
WRAP:Web Rephrase Augmented Pretraining

Prior approaches to generating synthetic textbook quality data using LLMs such as [ Phi 1 & Phi 1.5 ] required a language model that contains sufficient world knowledge to generate articles worth training on, thereby increasing generation cost; and a careful selection of prompts that enable generating high quality, and diverse articles that fill any knowledge gaps in the synthetic corpus. This approach has the potential of inadvertently creeping in biases in the language models as opposed to those trained on the natural diversity of the web.
As a remedy to these challenges this study proposes WRAP that leverages the natural diversity of articles on the web, allowing one to utilize significantly smaller LLMs (than GPT-3.5) to generate high-quality paraphrases of noisy and unstructured articles on the web.
This work has attempted rephrasing documents on the web in four different styles: Easy, Medium, Hard and Q/A using a frozen Mistral-7B instruction-tuned model.

The model output is used to create a parallel corpus of “high-quality” synthetic data corresponding to the original noisy web data. Each example has a maximum of 300 tokens, decided based on the empirical observation that asking an LLM to rephrase more than 300 tokens, often led to loss of information.
This method although incorporates the information diversity found on the internet, it does not incorporate the noise in real data, such as typos and linguistic errors which helps the LLMs not fail in user facing situations. In order to incorporate this style diversity in language modeling, real and synthetic data are sampled in a 1:1 ratio.
Implementation Details
Decoder only transformers are trained at three different scales for a maximum length of 1024.

Evaluation
Perplexity
- Models trained on the C4 dataset or a stylistic rephrase of the same were evaluated on 21 sub-domains of the Pile dataset, created from the first 10,000 documents of each domain.
- The evaluation focuses on the perplexity of the model on these subsets
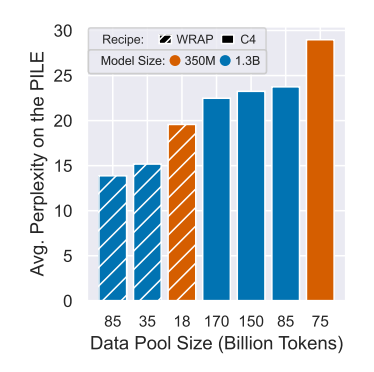
- Models trained for fewer tokens (150B) and smaller models (350M) outperform those trained on the full C4 for 300B tokens, showing faster learning with synthetic rephrases.

- In specific domains like ArXiv and HackerNews, training with synthetic data reduced perplexity by nearly 3x compared to models trained on real data alone, suggesting a significant performance advantage of synthetic data pre-training.
- On average, across multiple subsets of the Pile, models improved perplexity by 50% over those trained on real data alone.
- A notable learning speed-up was observed, where at the first checkpoint (10B tokens) of WRAP training, the average perplexity on the Pile was lower than that achieved by pre-training on C4 for 15 checkpoints, indicating a 15x pre-training speed-up.
Zero-shot Tasks
- Evaluation on 13 different zero-shot benchmarks covering common sense reasoning, language and knowledge understanding, and mathematical reasoning.
- Baseline methods include training on different sizes of the C4 dataset, the RefinedWeb Dataset, and comparisons with Pythia-1.4B and TinyLlama models.
General Improvements:
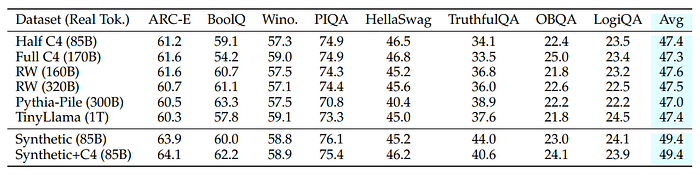
- Models trained on synthetic data combined with the C4 dataset showed higher average performance (49.4%) compared to those trained only on the real C4 dataset (47.4%) (Referenced in Table 1).
- The inclusion of synthetic data enhances the general understanding capabilities of NLP models.
- The TinyLlama model, despite being trained with significantly more compute and data, performs comparably to other models, suggesting minimal gains from adding more real data.
Specialized Knowledge Tasks:
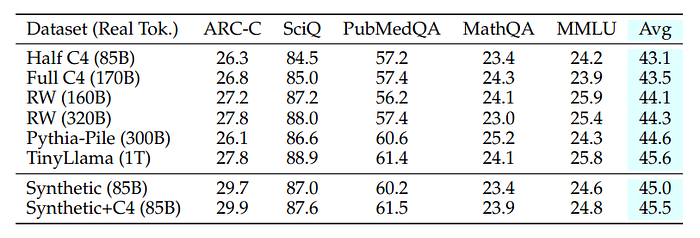
- Synthetic data does not impart new knowledge but helps in faster pre-training.
- Larger datasets improve performance by exposing the LLM to more “knowledge”.
- Performance improvements saturate with very large datasets; for example, the RefinedWeb (320B) model only slightly outperforms the RefinedWeb (160B) model.
Specific Improvements:
- The Synthetic (85B) model showed the maximum improvement on the TruthfulQA dataset, significantly outperforming other models.
- Adding real data to the synthetic model reduced performance on TruthfulQA by 4%, indicating a dilution of benefits from synthetic data when combined with real data.
- Other datasets like HellaSwag and BoolQ showed benefits from incorporating combinations of C4 and synthetic rephrases.
Analysis and Ablations
Real vs. Synthetic Data:
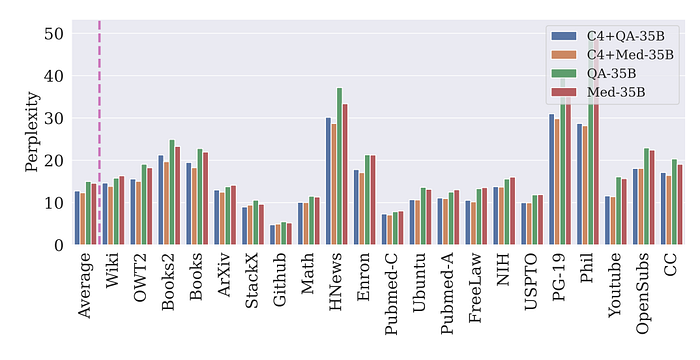
- Synthetic data alone can lead to strong performance on QA tasks but shows significant degradation in perplexity on Pile perplexity across many sub-domains.

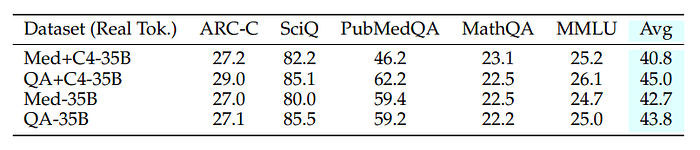
- Real data improves zero-shot performance, highlighting the importance of real data in training .
Combining Multiple Synthetic Datasets:
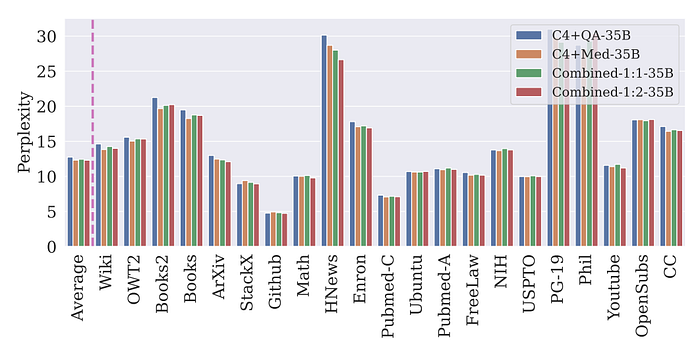
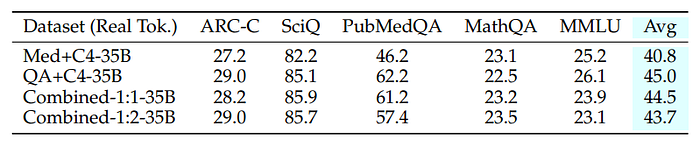

- Combining multiple synthetic styles with C4 data shows a small improvement in average perplexity on the Pile, with certain domains benefiting more from specific synthetic styles.
Quality of Re-phrasers:
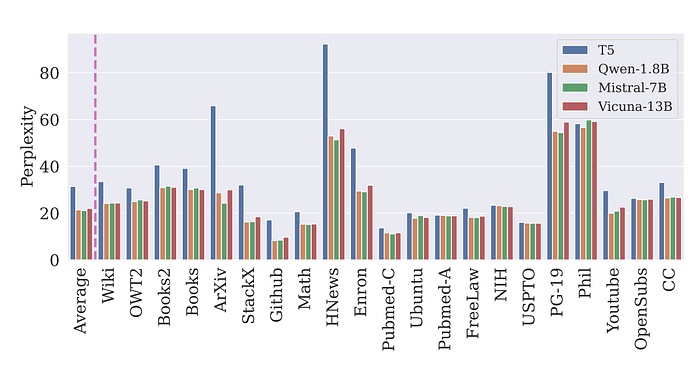
- Pre-training on data generated by smaller re-phrase models like Qwen-1.8B and Mistral-7B achieves lower perplexity than larger models, indicating the effectiveness of high-quality re-phrasers (Figure 5).
Synthetic Data vs. Augmentations:
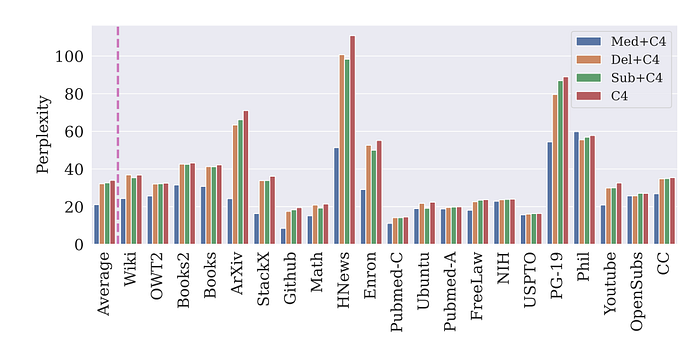
- Models trained on combinations of real and synthetic data perform significantly better than those trained on augmented data, suggesting synthetic data provides more than just augmentation benefits.
Impact of Synthetic Data Style:
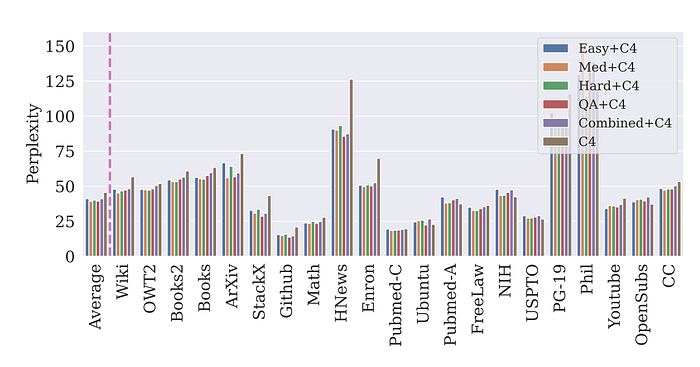
- No single style of synthetic data performs best across all domains, but training with combinations of real C4 and synthetic data matching the domain style improves performance.
- An oracle selecting the best synthetic style for each domain could improve perplexity by 16%, indicating the value of diverse data styles for generalization.
Data Leakage:
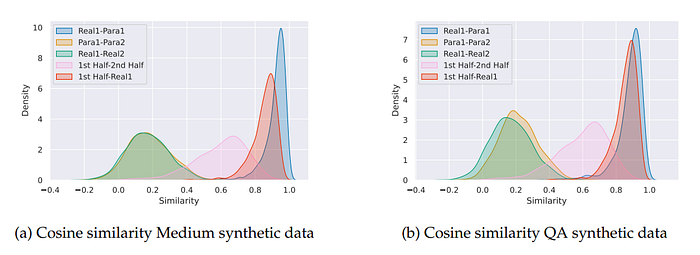
- Analysis shows high cosine similarity between synthetic and real data pairs, indicating that re-phrases maintain similar meaning without adding new information, thus minimizing concerns about data leakage.
Paper
Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling 2401.16380
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
