Papers Explained 05: Tiny BERT

Knowledge Distillation aims to transfer the knowledge of a large teacher network T to a small student network S. Let fT and fS represent the behavior functions of teacher and student networks, respectively.

In the context of Transformer distillation, the output of MHA layer or FFN layer, or some intermediate representations (such as the attention matrix A) can be used as behavior function. Formally, KD can be modeled as minimizing the following objective function:

where L(·) is a loss function that evaluates the difference between teacher and student networks, x is the text input and X denotes the training dataset.
Assuming that the student model has M Transformer layers and teacher model has N Transformer layers, we start with choosing M out of N layers from the teacher model for the Transformer-layer distillation. Then a function n = g(m) is defined as the mapping function between indices from student layers to teacher layers.
Thus, the student can acquire knowledge from the teacher by minimizing the following objective:

where Llayer refers to the loss function of a given model layer. and λm is the hyperparameter that represents the importance of m-th layers’s distillation.
Transformer Layer Distillation


where h is the number of attention heads and Ai refers to the attention matrix corresponding to the i-th head.

where the matrics HS and HT refer to hidden states of student and teacher networks respectively. The matrix Wh is a learnable linear transformation which transforms the hidden states of student network into the same space as the teacher network’s states.
Embedding Layer Distillation

where the matrices ES and ET refer to the embeddings of student and teacher networks, respectively. The matrix We is a linear transformation playing a similar role as Wh.
Prediction Layer Distillation

where ZT and zS are the logits vectors predicted by the student and teacher respectively and t means the temperature value. In the experiments, it was found that t = 1 performs well.
Unified Distillation Loss
Using the above distillation objectives, we can unify the distillation loss of the corresponding layers between the teacher and the student network:

TinyBERT Learning
TinyBERT proposed a novel two-stage learning framework including the general distillation and the task-specific distillation.
General distillation helps TinyBERT learn the rich knowledge embedded in pre-trained BERT, which plays an important role in improving the generalization capability of TinyBERT. The task-specific distillation further teaches TinyBERT the knowledge from the fine-tuned BERT.
TinyBERT Settings
TinyBERT4
- Student: TinyBERT4 (M=4, d=312, d’=1200 h=12) has a total of 14.5M parameters
- Teacher: BERT BASE (M=12, d=768, d’=3072 h=12) has a total of 109M parameters
- g(m) = 3m, \lambda = 1λ=1
TinyBERT6
- Student: TinyBERT6 (M=6, d=768, d’=3072 h=12) has a total of 14.5M parameters
- Teacher: BERT BASE (M=12, d=768, d’=3072 h=12) has a total of 109M parameters
- g(m) = 2m, \lambda = 1λ=1
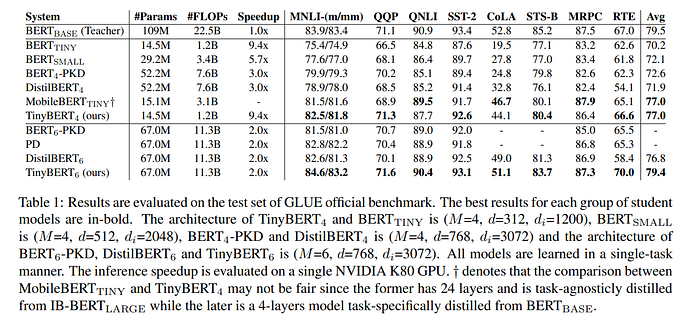
Results
Paper
TinyBERT: Distilling BERT for Natural Language Understanding 1909.10351
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!