Paper Explained 144: Granite Code Models

This paper introduces a series of decoder-only code models (3B, 8B, 20B, 34B) for code generative tasks, trained with code written in 116 programming languages, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Granite Code models have two main variants:
- Granite Code Base: base foundation models for code-related tasks;
- Granite Code Instruct: instruction following models fine tuned using a combination of Git commits paired with human instructions and open-source synthetically generated code instruction datasets.
The project is available at GitHub.
Data Collection
Data Crawling and Filtering
The pretraining code data was sourced from a combination of publicly available datasets like Github Code Clean, StarCoderdata, and additional public code repositories and issues from GitHub. Raw data is filtered to retain a list of 116 programming languages out of 300+ languages based on file extension.

Four key rules to filter out lower quality code:
- Remove files with fewer than 25% alphabetic characters.
- Except for the XSLT language, filter out files where the string “<?xml version=” appears within the first 100 characters.
- For HTML files, only keep files where the visible text makes up at least 20% of the HTML code and has a minimum length of 100 characters.
- For JSON and YAML files, only keep files that have a character count ranging from 50 to 5000 characters.
GitHub issues are filtered using a set of quality metrics that include removing auto-generated text, filtering out non-English issues, excluding comments from bots, and using the number of users engaged in the conversation as an indicator of quality.
Exact and Fuzzy Deduplication
For exact deduplication, SHA256 hash is computed on the document content and records having identical hashes are removed.
Fuzzy deduplication is applied afterward with the goal of removing code files that may have slight variations and thereby unbiasing the data further. A two-step method is used:
- Compute MinHashes of all the documents and then utilize Locally Sensitive Hashing (LSH) to group documents based on their MinHash fingerprints
- Measure Jaccard similarity between each pair of documents in the same bucket and annotate documents except one as duplicates based on a similarity threshold of 0.7.
HAP, PII, Malware Filtering
To reduce the likelihood of generating hateful, abusive, or profane (HAP) language from the models, a dictionary of HAP keywords i’s created and then each code document is annotated with the number of occurrences of such keywords in the content including comments. Documents exceeding a contain threshold are removed.
StarPII model is used to detect IP addresses, keys, email addresses, names, user names, and passwords found in the content. The PII redaction step replaces the PII text with the corresponding tokens ⟨NAME⟩, ⟨EMAIL⟩, ⟨KEY⟩, ⟨PASSWORD⟩ and change the IP address with a synthetically generated IP address.
The datasets are scanned using ClamAV5 to identify and remove instances of malware in the source code.
Natural Language Datasets
Web documents (Stackexchange, CommonCrawl), mathematical web text (OpenWebMath, StackMathQA), academic text (Arxiv, Wikipedia), and instruction tuning datasets (FLAN HelpSteer)are used as the Natural Language Datasets.
Model Architecture
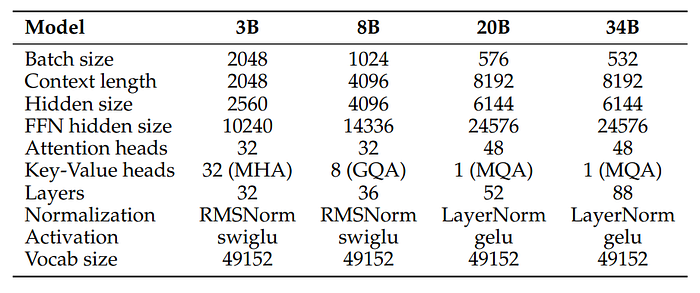
All the model architectures use pre-normalization i.e., normalization applied to the input of attention and MLP blocks.
- 3B: uses RoPE embedding and Multi-Head Attention.
- 8B: uses Grouped-Query Attention (GQA) as it offers a better tradeoff between model performance and inference efficiency at this scale.
- 20B: uses learned absolute position embeddings. and Multi-Query Attention.
- 34B: follows depth upscaling of the 20B model.
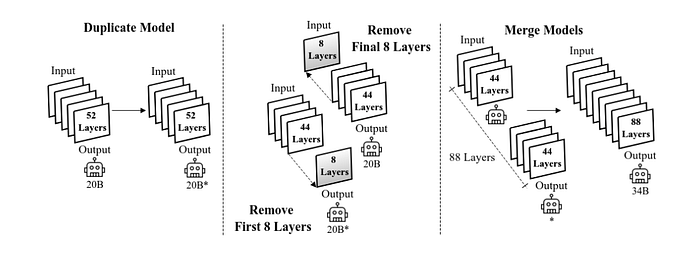
The 20B code model with 52 layers is duplicated and then final 8 layers are removed from the original model and initial 8 layers from its duplicate to form two models. Finally, both models are concatenated to form the Granite-34B-Code model with 88 layers.
Pretraining
Granite Code models are trained on 3.5 to 4.5T tokens of code data and natural language datasets related to code, tokenized via byte pair encoding (BPE) employing the same tokenizer as StarCoder.
Phase 1 (code only training):
- 3B and 8B models are trained for 4 trillion tokens of code data comprising 116 languages.
- The 20B parameter model is trained on 3 trillion tokens of code.
- The 34B model is trained on 1.4T tokens after the depth upscaling which is done on the 1.6T checkpoint of the 20B model.
Phase 2 (code + language training):
- Additional high-quality publicly available data from various domains, including technical, mathematics, and web documents, is included to further improve the model’s performance in reasoning and problem solving skills, which are essential for code generation.
- All the models are trained for 500B tokens (80% code and 20% language data).
Training Objective
Causal language modeling objective and Fill-In-The-Middle (FIM) objective with both PSM (Prefix-Suffix-Middle) and SPM (Suffix-Prefix-Middle) modes are used to train all the models.
The overall loss is computed as a weighted combination of the 2 objectives:
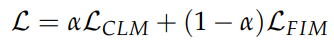
Empirically α = 0.5. FIM objective is only used during pre training, and dropped during instruction fine tuning i.e. set α = 1.
Instruction Tuning
Granite Code Instruct models are trained on the following types of data:
- Code Commits Dataset: CommitPackFT, a filtered version of full CommitPack dataset across 92 programming languages.
- Math Datasets: MathInstruct and MetaMathQA
- Code Instruction Datasets: Glaive-Code-Assistant-v3, Self-OSS-Instruct-SC2, Glaive-Function-Calling-v2, NL2SQL and few synthetically generated API calling datasets
- Language Instruction Datasets: High-quality datasets like HelpSteer, an open license-filtered version of Platypus including a collection of hardcoded prompts to ensure the model generates correct outputs given inquiries about its name or developers.
Evaluation
Granite Code models are evaluated on a wide variety of tasks, including code generation, code explanation, code fixing, code editing, math reasoning, etc
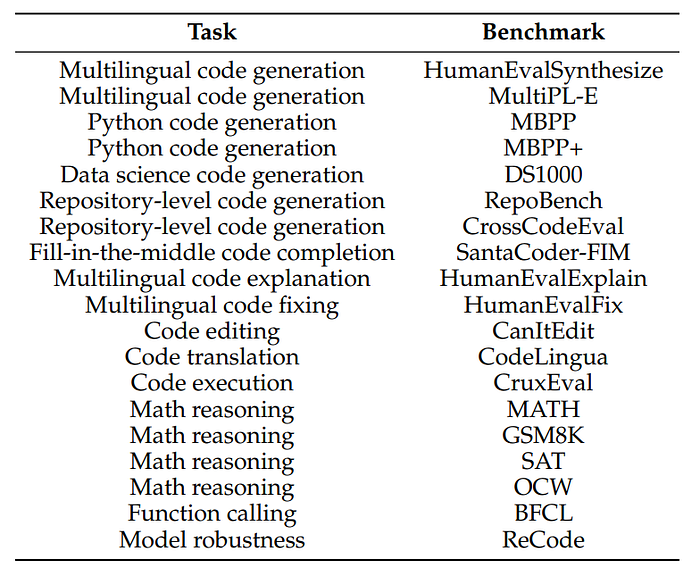
HumanEvalSynthesize: Multilingual Code Generation in 6 Languages
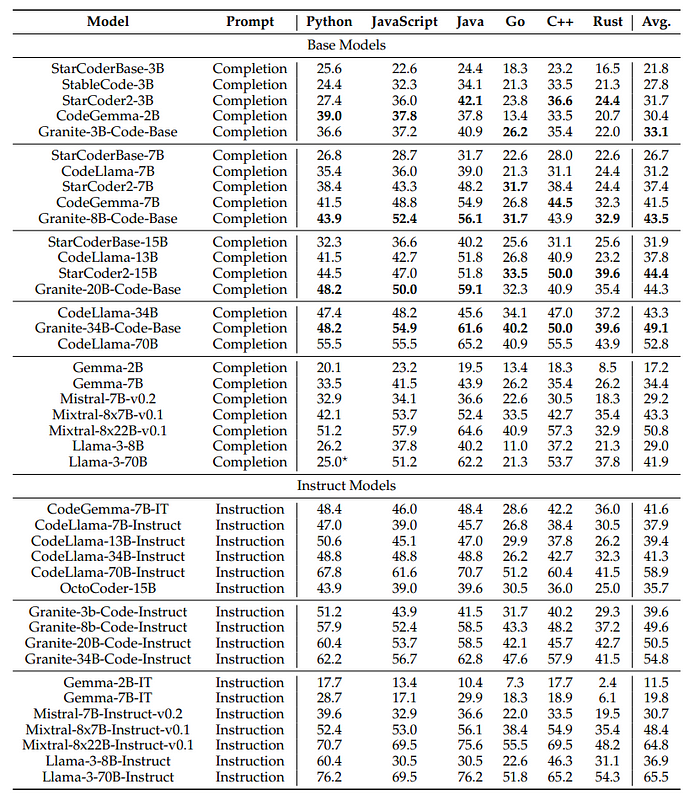
- Granite-3B-Code-Base is the best performing small model, with a +3% improvement over CodeGemma-2B.
- Among base models, Granite Code models achieve the best average performance at the 7B-8B scale, the second-best average performance at the 13B-20B size models, and are very close to the best model (StarCoder2–15B) with a difference of only 0.1%.
- Granite-34B-Code-Base achieves a much better performance on other languages than CodeLlama34B, leading to a 4% improvement on average across six languages.
- Among instruction models, Granite Code models consistently outperform equivalent size CodeLlama models; the 3B, 8B, and 20B models even outperform larger CodeLlama models by a significant margin.
- The smallest model, Granite-3B-CodeInstruct, surpasses the performance of CodeLlama-34B-Instruct.
- Granite Code models outperform larger state-of-the-art open-source general-purpose language models, including Gemma, Mixtral, and Llama 3 series models.
MultiPL-E: Multilingual Code Generation in 18 Languages
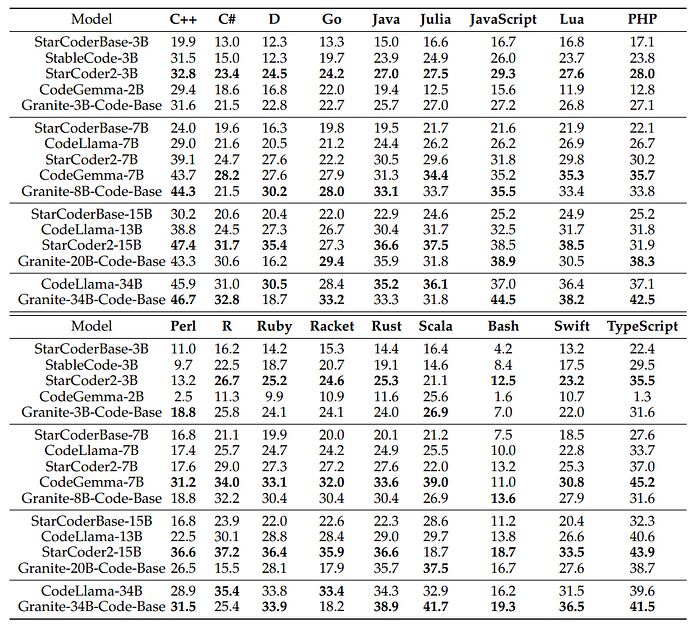
- No single model works best across all languages and model sizes.
- Granite-8B-Code-Base performs best on 16/18 programming languages compared to CodeLlama-7B.
- StarCoder2–15B performs best among medium models.
- Granite-34B-Code-Base outperforms CodeLlama-34B on most languages, demonstrating its effectiveness in code generation.
MBPP and MBPP+: Code Generation in Python
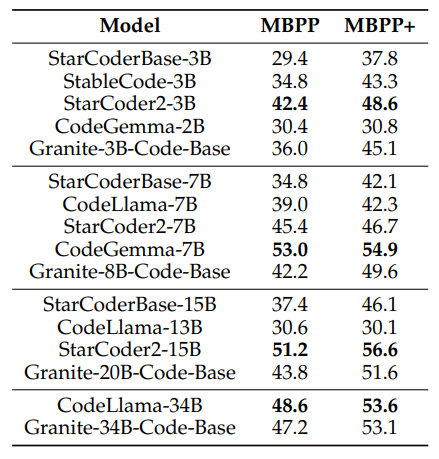
- Granite3B-Code-Base outperformed CodeGemma-2B but was outperformed by StarCoder2–3B on both MBPP and MBPP+ benchmarks.
- At mid parameter ranges, Granite Code models were superior to CodeLlama-7B and CodeLLama-13B by approximately 5% and 15%, respectively, on average.
- Granite-34B-Code-Base was highly competitive with CodeLlama-34B, with an average difference of only 0.9% across both benchmarks.
DS1000: Data Science Tasks in Python
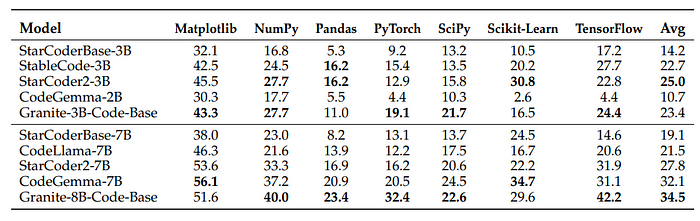
- StarCoder2–3B (small model) performs best among small models.
- Granite-3B-Code-Base ranks second, outperforming CodeGemma-2B by over 12 points across all libraries.
- Granite-8B-Code-Base achieves the highest average performance of 34.5%, surpassing other models with similar parameter sizes.
- Granite Code models show high accuracy, outperforming CodeGemma at 2B-3B scale and StarCoder2 at 7B-8B scale, as well as half the size of CodeLlama models.
RepoBench, CrossCodeEval: Repository-Level Code Generation
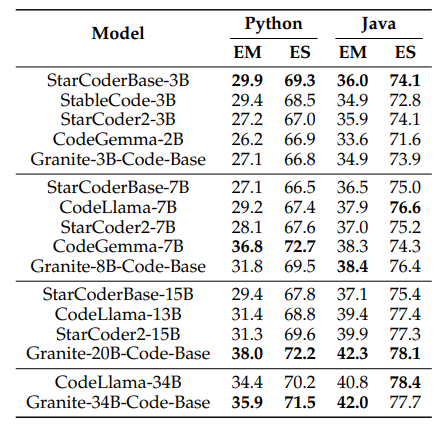
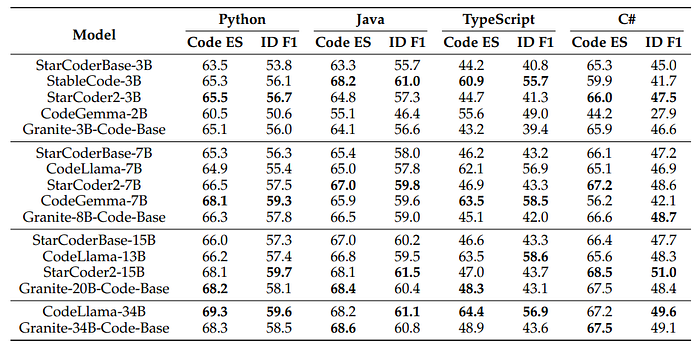
- Granite-3B-CodeBase performed notably among smaller models, with StarCoderBase-3B leading in performance metrics.
- Medium models like Granite-8B-CodeBase showed very strong performance on Java and ranked second best in Python, with CodeGemma-7B being the top performer on both languages.
- Larger models such as Granite-20B-Code demonstrated superior performance across all metrics compared to StarCoder2–15B and CodeLlama-34B for Java, Python, C#, and TypeScript.
FIM: Infilling Evaluations
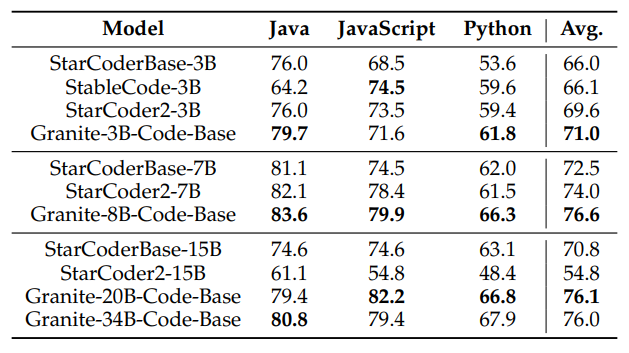
- Granite Code models outperform StarCoder and StarCoder2 across all model sizes, indicating a significant advantage in code completion tasks.
- There is no observed performance improvement when scaling the model sizes from 8 billion (B) to 34B parameters, suggesting that smaller models are as effective for the task at hand.
Code Explanation and Fixing
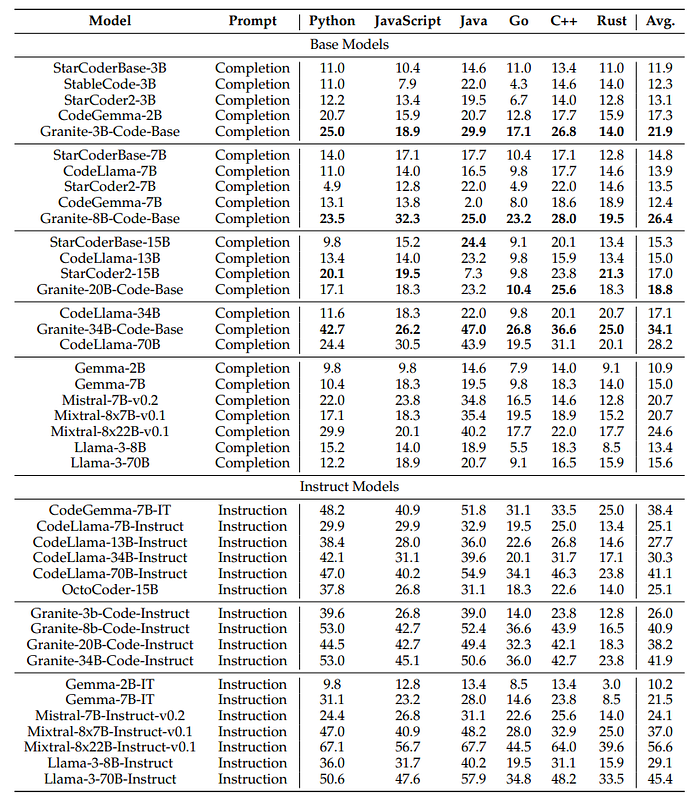
- Granite Code Base models outperform other state-of-the-art (SOTA) base code LLMs like StarCoder2 and CodeGemma by a significant margin.
- Granite-8B-Code-Base outperforms CodeLlama-34B by 9.3% on average, performing close to CodeLlama-70B.
- After instruction tuning, all base models show improved performance across languages.
- Granite-34B-Code-Instruct performs the best with an average score of 41.9%, closely followed by CodeLlama-70B-Instruct with a score of 41.1%.
- CodeGemma-7B-IT shows the most improvement from instruction tuning but is still 2.5% behind Granite-8B-CodeInstruct on average.
- Mixtral-8x22B-Instruct-v0.1 performs best among all models with a significant margin, indicating the potential advantage of larger models and general natural language data training.
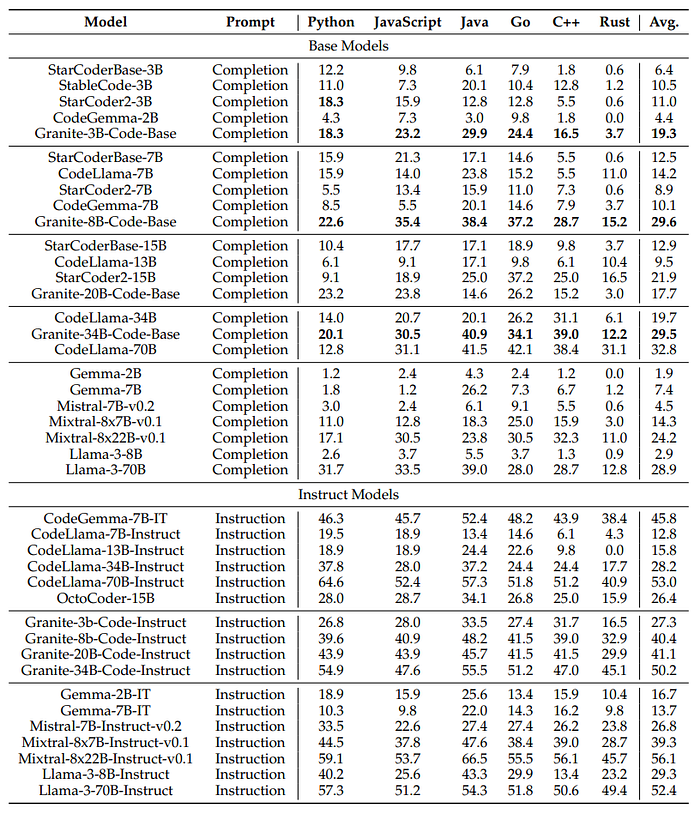
- Granite Code Base models again outperform other base models, with Granite-8B-Code-Base performing impressively close to CodeLlama-70B and Llama-3–70B.
- After instruction tuning, there is a performance improvement for almost all models, especially for the 8B and 20B instruct models.
- Large instruct models (over 34B parameters) show a significant performance improvement of about 10 points.
- Granite-34B-Code-Instruct performs similarly to other large models with at least twice the parameters, offering a better cost and performance balance.
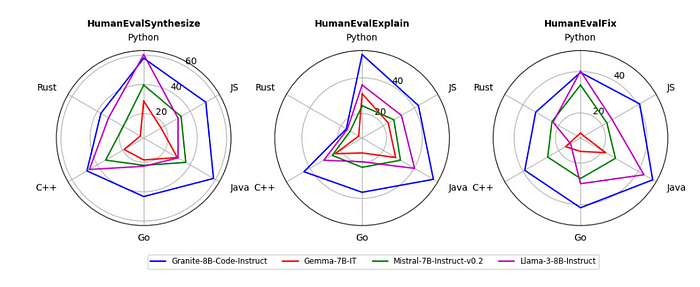
Code Editing and Translation
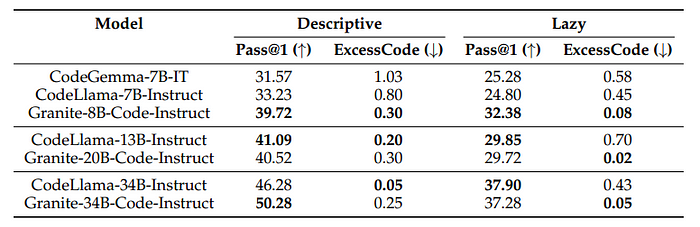
- Granite Code models had higher pass rates and fewer unnecessary code changes compared to CodeGemma and CodeLlama, indicating better understanding of user intentions.
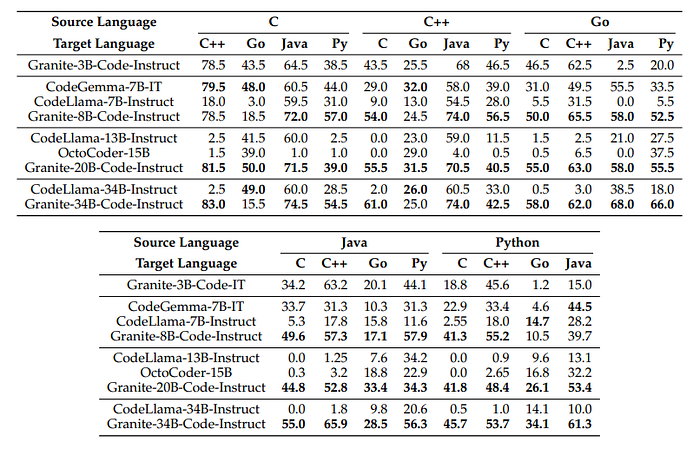
- Instruction-tuned models generally outperform base models in understanding requests for code translation.
- Granite Code and CodeGemma models produced well-formatted outputs that facilitated easy parsing, contrasting with the more challenging outputs from CodeLLama.
- The inclusion of extra metadata and explanations in the generated code significantly impacts the success rate of translations.
- The choice of source and target languages can affect translation success rates.
Code Reasoning, Understanding and Execution
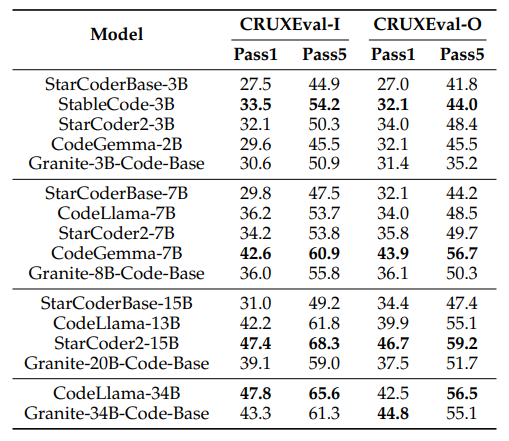
- Granite-3B-Code-Base outperforms CodeGemma-2B on CRUXEval-I but lags behind on CRUXEval-O
- CodeGemma-7B outperforms all the models on both tasks at 7B-8B parameters
- Granite-34B-Code-Base lags behind CodeLlama-34B on CRUXEval-I but outperforms on CRUXEval-O
- Performance increases as the size of the Granite Code models scales from 3B to 34B parameters
Math Reasoning
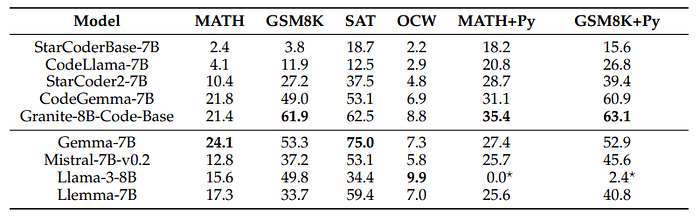
- Despite not being specifically tuned for mathematical reasoning, Granite-8B-Code-Base shows impressive reasoning ability, outperforming most existing 7B to 8B models.
- While other models may be particularly strong on a few tasks, our model consistently achieves top-1 or top-2 performance on all tasks.
Calling Functions and Tools
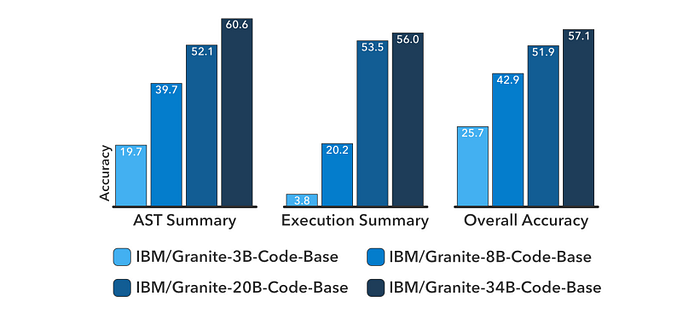
- The scaling of the model (from 3B to 34B parameters) significantly improved the function/tool calling capabilities.
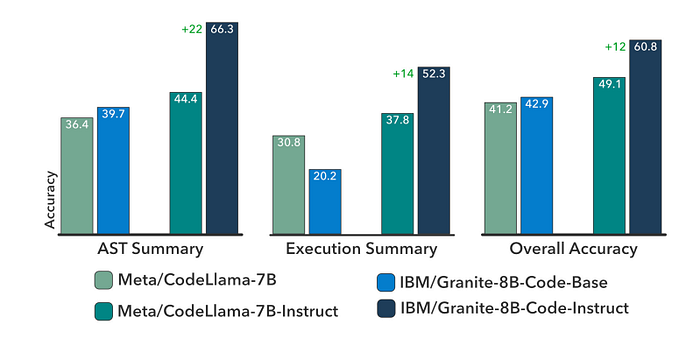
- Instruction tuning led to performance improvements for both Granite Code models and CodeLlama-7B.
- The most significant improvement was observed in the Granite Code models, with an increase of +17.88% in overall accuracy from Granite-8B-Code-Base to Granite-8B-Code-Instruct.
Paper
Granite Code Models: A Family of Open Foundation Models for Code Intelligence 2405.04324
Recommended Reading [LLMs for Code]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
