Nov 6, 2024
9 stories
4 saves
Reorganizes tokens using layout information, combines text and visual embeddings, utilizes multi-modal transformers with spatial aware disentangled attention.


A unified text-image multimodal Transformer to learn cross-modal representations, that imputs concatenation of text embedding and image embedding.
Introduced Bi-directional attention complementation mechanism (BiACM) to accomplish the cross-modal interaction of text and layout.
Built upon BERT, encodes relative positions of texts in 2D space and learns from unlabeled documents with area masking strategy.


Encoder-only transformer with a CNN backbone for visual feature extraction, combines text, vision, and spatial features through a multi-modal self-attention layer.


Utilises BERT as the backbone and feeds text, 1D and (2D cell level) embeddings to the transformer model.


Uses a multi-modal Transformer model, to integrate text, layout, and image in the pre-training stage, to learn end-to-end cross-modal interaction.
Utilises RoBERTa as the backbone and adds Layout embeddings along with relative bias.
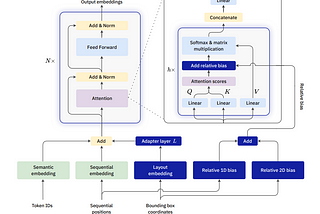
Utilises BERT as the backbone, adds two new input embeddings: 2-D position embedding and image embedding (Only for downstream tasks).