Aug 9, 2024
10 stories
5 saves
Enhances the DeBERTa architecture by introducing replaced token detection (RTD) instead of mask language modeling (MLM), along with a novel gradient-disentangled embedding sharing method, exhibiting superior performance across various natural language understanding tasks.


Enhances BERT and RoBERTa through disentangled attention mechanisms, an enhanced mask decoder, and virtual adversarial training.


Compressed and faster version of the BERT, featuring bottleneck structures, optimized attention mechanisms, and knowledge transfer.


A speed-tunable encoder with adaptive inference time having branches at each transformer output to enable early outputs.

Distills BERT on very large batches leveraging gradient accumulation, using dynamic masking and without the next sentence prediction objective.


Presents certain parameter reduction techniques to lower memory consumption and increase the training speed of BERT.


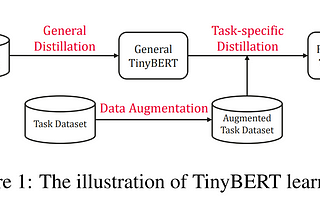
Uses attention transfer, and task specific distillation for distilling BERT.

A modification of BERT that uses siamese and triplet network structures to derive sentence embeddings that can be compared using cosine-similarity.
Built upon BERT, by carefully optimizing hyperparameters and training data size to improve performance on various language tasks.
Introduced pre-training for Encoder Transformers. Uses unified architecture across different tasks.